Código
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import polars as pl
import pymc as pm
import pytensor.tensor as pt
c_orange = "#f08533"
c_blue = "#3b78b0"
c_red = "#d1352c"import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import polars as pl
import pymc as pm
import pytensor.tensor as pt
c_orange = "#f08533"
c_blue = "#3b78b0"
c_red = "#d1352c"Mientras scrapeaba datos sobre los tiros libres de los rookies en la NBA durante la temporada 2024-25, me encontré con este artículo, donde se concluye que existe un efecto de “precalentamiento”: los jugadores de básquet tienden a fallar más los primeros disparos que el resto. El hallazgo me pareció interesante y lógico, y empecé a preguntarme si valía la pena realizar un análisis similar con los datos que estaba recolectando. Y bueno, acá estamos.
El siguiente data frame contiene información sobre los tiros libres realizados por los rookies de la temporada 2024-25 de la NBA. En este caso, las columnas relevantes son la identificación del jugador (player_id), el orden del disparo (description) y si el lanzamiento fue convertido (success).
df = (
pl.read_parquet("../data.parquet")
.select("game_date", "matchup", "player_id", "player_name", "description", "success")
)
df| game_date | matchup | player_id | player_name | description | success |
|---|---|---|---|---|---|
| date | str | i32 | str | str | bool |
| 2025-04-05 | "MEM @ DET" | 1641744 | "Edey, Zach" | "Free Throw 1 of 2" | false |
| 2025-04-05 | "MEM @ DET" | 1641744 | "Edey, Zach" | "Free Throw 2 of 2" | false |
| 2025-01-18 | "PHI @ IND" | 1641737 | "Bona, Adem" | "Free Throw 1 of 1" | true |
| 2025-01-18 | "PHI @ IND" | 1641737 | "Bona, Adem" | "Free Throw 1 of 2" | false |
| 2025-01-18 | "PHI @ IND" | 1641737 | "Bona, Adem" | "Free Throw 2 of 2" | true |
| … | … | … | … | … | … |
| 2024-11-06 | "MEM vs. LAL" | 1642530 | "Kawamura, Yuki" | "Free Throw 1 of 2" | true |
| 2024-11-06 | "MEM vs. LAL" | 1642530 | "Kawamura, Yuki" | "Free Throw 2 of 2" | true |
| 2025-03-12 | "MEM vs. UTA" | 1641744 | "Edey, Zach" | "Free Throw 1 of 1" | false |
| 2024-11-22 | "NOP vs. GSW" | 1641810 | "Reeves, Antonio" | "Free Throw 1 of 2" | true |
| 2024-11-22 | "NOP vs. GSW" | 1641810 | "Reeves, Antonio" | "Free Throw 2 of 2" | false |
En la NBA, los tiros libres pueden darse en series de 1, 2 o 3 intentos. Nuestra primera tarea es mapear los valores de description a un valor numérico que represente el orden del disparo dentro de su serie.
throw_order = {
"Free Throw 1 of 1": 1,
"Free Throw 1 of 2": 1,
"Free Throw 1 of 3": 1,
"Free Throw 2 of 2": 2,
"Free Throw 2 of 3": 2,
"Free Throw 3 of 3": 3,
"Free Throw Clear Path 1 of 2": 1,
"Free Throw Clear Path 2 of 2": 2,
"Free Throw Flagrant 1 of 1": 1,
"Free Throw Flagrant 1 of 2": 1,
"Free Throw Flagrant 2 of 2": 2,
"Free Throw Technical": 1,
}
df = df.with_columns(
pl.col("description").replace_strict(throw_order, return_dtype=pl.Int64).alias("order")
)
df| game_date | matchup | player_id | player_name | description | success | order |
|---|---|---|---|---|---|---|
| date | str | i32 | str | str | bool | i64 |
| 2025-04-05 | "MEM @ DET" | 1641744 | "Edey, Zach" | "Free Throw 1 of 2" | false | 1 |
| 2025-04-05 | "MEM @ DET" | 1641744 | "Edey, Zach" | "Free Throw 2 of 2" | false | 2 |
| 2025-01-18 | "PHI @ IND" | 1641737 | "Bona, Adem" | "Free Throw 1 of 1" | true | 1 |
| 2025-01-18 | "PHI @ IND" | 1641737 | "Bona, Adem" | "Free Throw 1 of 2" | false | 1 |
| 2025-01-18 | "PHI @ IND" | 1641737 | "Bona, Adem" | "Free Throw 2 of 2" | true | 2 |
| … | … | … | … | … | … | … |
| 2024-11-06 | "MEM vs. LAL" | 1642530 | "Kawamura, Yuki" | "Free Throw 1 of 2" | true | 1 |
| 2024-11-06 | "MEM vs. LAL" | 1642530 | "Kawamura, Yuki" | "Free Throw 2 of 2" | true | 2 |
| 2025-03-12 | "MEM vs. UTA" | 1641744 | "Edey, Zach" | "Free Throw 1 of 1" | false | 1 |
| 2024-11-22 | "NOP vs. GSW" | 1641810 | "Reeves, Antonio" | "Free Throw 1 of 2" | true | 1 |
| 2024-11-22 | "NOP vs. GSW" | 1641810 | "Reeves, Antonio" | "Free Throw 2 of 2" | false | 2 |
Podemos observar que los primeros intentos suelen fallarse con mayor frecuencia que los segundos, y que estos, a su vez, se fallan más que los terceros.
df_summary = (
df
.group_by("order")
.agg(pl.col("success").sum().alias("y"), pl.len().alias("n"))
.with_columns((pl.col("y") / pl.col("n")).alias("p"))
.sort("order")
)
df_summary| order | y | n | p |
|---|---|---|---|
| i64 | u32 | u32 | f64 |
| 1 | 1435 | 2069 | 0.693572 |
| 2 | 1227 | 1625 | 0.755077 |
| 3 | 23 | 28 | 0.821429 |
Como primer paso, utilizamos un modelo que agrupa los disparos de todos los jugadores, los considera equivalentes, más de lo mismo. Definimos \(Y_1\) como la cantidad de aciertos en primeros disparos y \(Y_2\) como la cantidad de aciertos en segundos disparos. Luego, \(\pi_1\) representa la probabilidad de acertar en un primer intento y \(\pi_2\) en un segundo.
\[ \begin{aligned} Y_1 &\sim \text{Binomial}(N_1, \pi_1) \\ Y_2 &\sim \text{Binomial}(N_2, \pi_2) \\ \pi_1 &\sim \text{Beta}(4, 2) \\ \pi_2 &\sim \text{Beta}(4, 2) \\ \end{aligned} \]
En PyMC, tenemos:
y = df_summary.head(2)["y"].to_numpy()
n = df_summary.head(2)["n"].to_numpy()
with pm.Model(coords={"order": [1, 2]}) as model:
pi = pm.Beta("pi", alpha=4, beta=2, dims="order")
y = pm.Binomial("y", p=pi, n=n, observed=y, dims="order")
idata = pm.sample(chains=4, random_seed=1211, nuts_sampler="nutpie", progressbar=False)
model.to_graphviz()
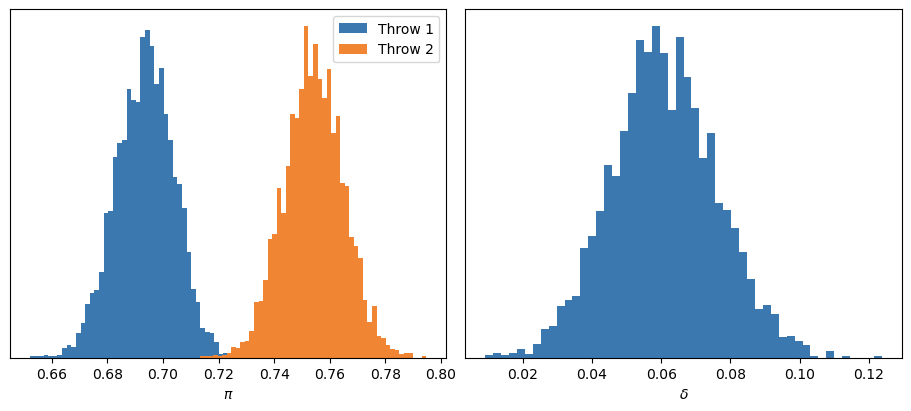
Calculamos \(\delta\) como la diferencia entre \(\pi_2\) y \(\pi_1\), y analizamos las distribuciones marginales a posteriori.
En primer lugar, los diagnósticos no indican problemas en el muestreo: \(\hat{R}\) cercano a 1, tamaños efectivos de muestra adecuados, etc.
idata.posterior["delta"] = idata.posterior["pi"].sel(order=2) - idata.posterior["pi"].sel(order=1)
az.summary(idata, var_names=["pi", "delta"])| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| pi[1] | 0.694 | 0.010 | 0.673 | 0.712 | 0.0 | 0.0 | 4040.0 | 2880.0 | 1.0 |
| pi[2] | 0.754 | 0.011 | 0.733 | 0.773 | 0.0 | 0.0 | 3996.0 | 2737.0 | 1.0 |
| delta | 0.061 | 0.015 | 0.030 | 0.088 | 0.0 | 0.0 | 4193.0 | 2918.0 | 1.0 |
Si nos enfocamos en la distribución a posteriori de \(\delta\), podemos ver que la probabilidad de que \(\delta\) sea mayor a 0 es igual a 1.
Así, llegamos a nuestra primera gran conclusión: efectivamente, la probabilidad de acertar en el segundo intento es mayor que en el primero. De hecho, la probabilidad de acierto se incrementa, en promedio, un 6 %. Y, con un alto grado de certeza, podemos afirmar que esta mejora se encuentra entre el 3 % y el 9 %.
El modelo anterior solo nos permite concluir que es más probable que un rookie acierte un segundo lanzamiento que un primero (y cuantificar la magnitud de la diferencia). Sin embargo, no podemos extraer conclusiones sobre jugadores individuales. Por ejemplo, no sabemos si este fenómeno de “precalentamiento” se presenta en todos ellos, ni si su intensidad varía de un jugador a otro.
Una alternativa sería ajustar pares de modelos beta-binomiales como los anteriores para cada jugador. Lamentablemente, dado que la cantidad de disparos varía entre apenas uno y unas pocas centenas, las distribuciones a posteriori pueden resultar extremadamente inciertas en algunos casos o excesivamente confiadas en otros.
Así llegamos a la alternativa bayesiana por excelencia: el modelo jerárquico. Bajo este enfoque, cada jugador tiene su propia probabilidad de acierto, pero dicha probabilidad proviene de una distribución común compartida con el resto. De este modo, las estimaciones son más estables y se evita el sobreajuste a los datos particulares de cada jugador, ya que la distribución a posteriori de cada uno está influenciada, en cierta medida, por la información del resto.
Los datos que necesitamos son la cantidad de disparos y aciertos en el primer y segundo intento para cada jugador. Por simplicidad, consideramos únicamente a los jugadores que realizaron al menos una serie de dos tiros libres.
df_agg = (
df
.group_by("player_id", "order")
.agg(
pl.col("success").sum().alias("y"),
pl.len().alias("n")
)
.sort("player_id", "order")
)
selected_ids = (
df_agg
.filter(pl.col("order") == 2, pl.col("n") > 0)
.get_column("player_id")
.unique()
.to_list()
)
df_model = (
df_agg
.filter(pl.col("player_id").is_in(selected_ids), pl.col("order") < 3)
.sort("player_id", "order")
)
df_model| player_id | order | y | n |
|---|---|---|---|
| i32 | i64 | u32 | u32 |
| 1630283 | 1 | 1 | 5 |
| 1630283 | 2 | 5 | 5 |
| 1630542 | 1 | 4 | 5 |
| 1630542 | 2 | 4 | 5 |
| 1630545 | 1 | 9 | 12 |
| … | … | … | … |
| 1642502 | 2 | 1 | 2 |
| 1642505 | 1 | 1 | 1 |
| 1642505 | 2 | 1 | 1 |
| 1642530 | 1 | 4 | 5 |
| 1642530 | 2 | 3 | 4 |
De manera distribucional, podemos representar al modelo de la siguiente manera:
\[\begin{aligned} Y_{i1} &\sim \text{Binomial}(N_{i1}, \pi_i) \\ Y_{i2} &\sim \text{Binomial}(N_{i2}, \theta_i) \\ \\ & \text{--- P(Free throw 1 is made) ---} \\ \pi_i &\sim \text{Beta}(\mu_\pi, \kappa_\pi) \\ \mu_\pi &\sim \text{Beta}(4, 2) \\ \kappa_\pi &\sim \text{InverseGamma}(0.5 \cdot 15, 0.5 \cdot 15 \cdot 10) \\ \\ & \text{--- P(Free throw 2 is made) --- } \\ \theta_i &= \pi_i + \delta_i \\ \delta_i &\sim \text{Normal}(\mu_\delta, \sigma^2_\delta) \\ \mu_\delta &\sim \text{Normal}(0, 0.15^2) \\ \sigma^2_\delta &\sim \text{InverseGamma}(0.5 \cdot 30, 0.5 \cdot 30 \cdot 0.05) \\ \end{aligned}\]donde \(i \in \{1, \dots, 92\}\) indexa a los jugadores.
En otras palabras, modelizamos la probabilidad de acierto en el segundo intento como la suma de la probabilidad de acierto en el primero (\(\pi_i\)) y un diferencial específico de cada jugador (\(\delta_i\)).
Las distribuciones a priori para \(\mu_\pi\) y \(\mu_\delta\) son levemente y moderadamente informativas, respectivamente. Por su parte, los priors asignados a \(\kappa_\pi\) y \(\sigma^2_\delta\) también son moderadamente informativos, aunque en este caso su función principal es favorecer la estabilidad del muestreo del posterior.
1y_1 = df_model.filter(pl.col("order") == 1)["y"].to_numpy()
y_2 = df_model.filter(pl.col("order") == 2)["y"].to_numpy()
n_1 = df_model.filter(pl.col("order") == 1)["n"].to_numpy()
n_2 = df_model.filter(pl.col("order") == 2)["n"].to_numpy()
2player_ids = df_model["player_id"].unique(maintain_order=True)
N = len(player_ids)
coords = {"player": player_ids}
with pm.Model(coords=coords) as model_h:
3 pi_mu = pm.Beta("pi_mu", alpha=4, beta=2)
pi_kappa = pm.InverseGamma("pi_kappa", alpha=0.5 * 15, beta=0.5 * 15 * 10)
pi_alpha = pi_mu * pi_kappa
pi_beta = (1 - pi_mu) * pi_kappa
pi = pm.Beta("pi", alpha=pi_alpha, beta=pi_beta, dims="player")
4 delta_mu = pm.Normal("delta_mu", mu=0, sigma=0.15)
delta_sigma = pm.InverseGamma("delta_sigma^2", 0.5 * 30, 0.5 * 30 * 0.05 ** 2) ** 0.5
delta = pm.Normal(
5 "delta", mu=delta_mu, sigma=delta_sigma, dims="player", initval=np.zeros(N)
)
6 theta = pm.Deterministic("theta", pt.clip(pi + delta, 0.0001, 0.9999), dims="player")
pm.Binomial("y_1", p=pi, n=n_1, observed=y_1, dims="player")
pm.Binomial("y_2", p=theta, n=n_2, observed=y_2, dims="player")pm.Beta.
initval: para que el algoritmo de inferencia comience en un punto válido del espacio paramétrico.
pt.clip: para asegurarnos que \(\pi_i + \delta_i\) se encuentre entre 0 y 1. Esto no afecta al posterior, pero es necesario para inicializar correctamente el algoritmo de muestreo.
Finalmente, así es como se ve una representación gráfica del modelo:

Gracias a nutpie, es posible obtener muestras fiables del posterior en muy pocos segundos.
Si bien los diagnósticos no se ven tan bien como en el modelo agrupado (lo cual es esperable en modelos jerárquicos), los valores son aceptables y podemos continuar con nuestro análisis.
with model_h:
idata_h = pm.sample(
chains=4,
target_accept=0.99,
nuts_sampler="nutpie",
random_seed=1211,
progressbar=False,
)
az.summary(idata_h, var_names=["pi_mu", "pi_kappa", "delta_mu", "delta_sigma^2"])| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| pi_mu | 0.698 | 0.015 | 0.670 | 0.727 | 0.000 | 0.000 | 1063.0 | 2206.0 | 1.00 |
| pi_kappa | 28.903 | 9.035 | 14.499 | 45.731 | 0.286 | 0.278 | 1001.0 | 1623.0 | 1.00 |
| delta_mu | 0.055 | 0.016 | 0.027 | 0.086 | 0.001 | 0.000 | 497.0 | 910.0 | 1.01 |
| delta_sigma^2 | 0.002 | 0.001 | 0.001 | 0.003 | 0.000 | 0.000 | 1262.0 | 2006.0 | 1.00 |
Los posteriors marginales de los parámetros poblacionales son los siguientes:
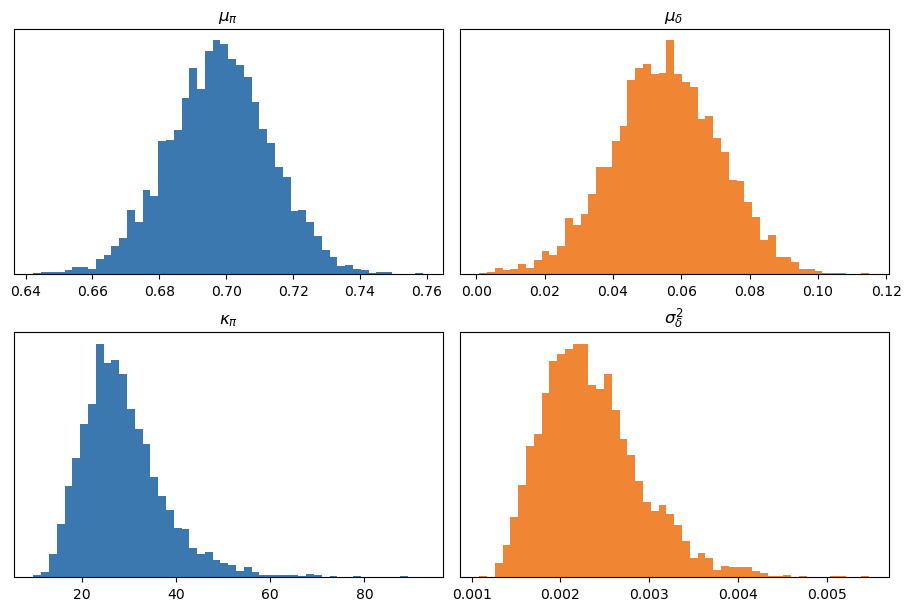
A simple vista, se observa que, en promedio, la probabilidad de acertar un primer lanzamiento ronda el 70 %, y que los segundos intentos tienen, en promedio, cerca de un 6 % más de probabilidad de ser convertidos. Aunque esto no resulte novedoso, es satisfactorio comprobar que las inferencias obtenidas con el modelo jerárquico son consistentes con los hallazgos anteriores.
Lo realmente interesante de este modelo jerárquico es que nos permite analizar las distribuciones a posteriori de \(\pi_i\), \(\theta_i\) y \(\delta_i\) a nivel individual, es decir, para cada jugador.
Sin embargo, visualizar estas distribuciones para todos ellos puede resultar poco práctico. Por eso, seleccionamos un subconjunto representativo de jugadores en función de sus valores de \(N_1\) (la cantidad de primeros lanzamientos). En concreto, conservamos a los 10 jugadores con mayor \(N_1\) y, entre el resto, los ordenamos de menor a mayor y elegimos uno cada dos posiciones para formar una muestra más manejable.
| player_id | player_name | y_1 | y_2 | n_1 | n_2 |
|---|---|---|---|---|---|
| i32 | str | u32 | u32 | u32 | u32 |
| 1642264 | "Castle, Stephon" | 128 | 121 | 192 | 152 |
| 1642274 | "Missi, Yves" | 63 | 64 | 112 | 92 |
| 1642259 | "Sarr, Alex" | 62 | 50 | 88 | 77 |
| 1642268 | "Collier, Isaiah" | 56 | 49 | 85 | 69 |
| 1642258 | "Risacher, Zaccharie" | 55 | 47 | 82 | 62 |
| 1642271 | "Filipowski, Kyle" | 47 | 46 | 81 | 62 |
| 1641744 | "Edey, Zach" | 54 | 36 | 76 | 51 |
| 1642377 | "Wells, Jaylen" | 62 | 44 | 73 | 56 |
| 1641842 | "Holland II, Ronald" | 51 | 41 | 70 | 52 |
| 1642270 | "Clingan, Donovan" | 33 | 29 | 60 | 44 |
| 1641824 | "Buzelis, Matas" | 45 | 43 | 59 | 49 |
| 1642273 | "George, Kyshawn" | 39 | 31 | 51 | 42 |
| 1642266 | "Walter, Ja'Kobe" | 34 | 32 | 47 | 36 |
| 1642347 | "Shead, Jamal" | 32 | 20 | 42 | 26 |
| 1641783 | "da Silva, Tristan" | 29 | 26 | 35 | 28 |
| 1642272 | "McCain, Jared" | 23 | 23 | 28 | 25 |
| 1642348 | "Edwards, Justin" | 17 | 15 | 24 | 22 |
| 1641810 | "Reeves, Antonio" | 16 | 12 | 21 | 14 |
| 1631232 | "Brooks Jr., Keion" | 12 | 10 | 17 | 13 |
| 1642277 | "Furphy, Johnny" | 11 | 7 | 13 | 9 |
| 1641736 | "Beekman, Reece" | 8 | 8 | 11 | 10 |
| 1642265 | "Dillingham, Rob" | 4 | 4 | 9 | 6 |
| 1630574 | "Hukporti, Ariel" | 2 | 4 | 7 | 6 |
| 1630283 | "Kelley, Kylor" | 1 | 5 | 5 | 5 |
| 1641989 | "Harkless, Elijah" | 2 | 1 | 3 | 3 |
| 1630762 | "Wheeler, Phillip" | 1 | 1 | 1 | 1 |
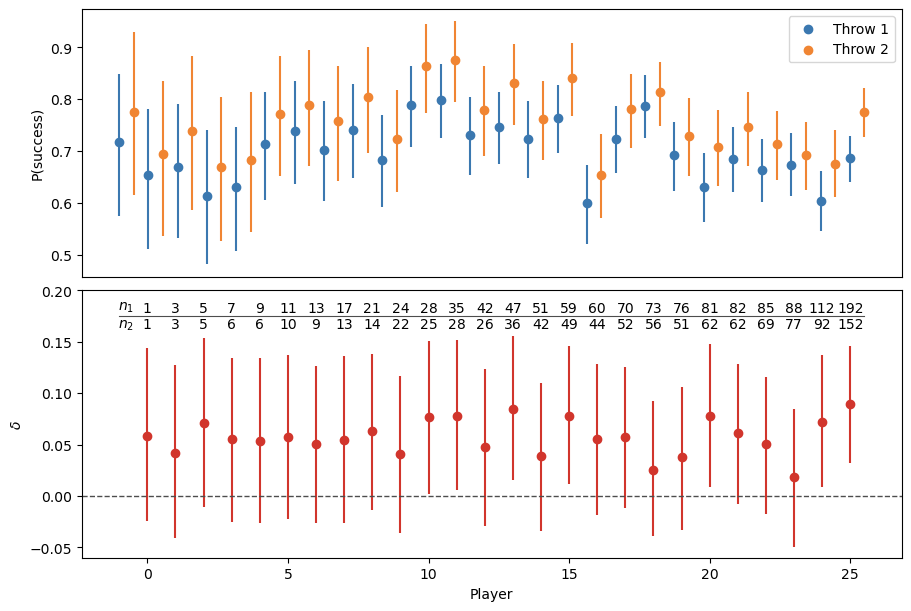
Luego, podemos visualizar los posterior marginales de \(\pi_i\), \(\theta_i\) y \(\delta_i\) para cada jugador seleccionado. Naturalmente, a medida que aumenta la cantidad de disparos observados, las distribuciones a posteriori se vuelven más estrechas, reflejando un mayor nivel de certidumbre.
En todos los casos, incluso cuando \(N_1 = 1\) y \(N_2 = 1\), la media a posteriori de \(\theta_i\) es mayor que la de \(\pi_i\).
Visto desde otro ángulo, en el panel inferior se observa que la media de \(\delta_i\) es siempre mayor que 0. Sin embargo, solo en aquellos casos en los que se registran cientos de lanzamientos puede concluirse, con probabilidad cercana a 1, que los jugadores son efectivamente mejores en los segundos intentos que en los primeros.
Como somos bayesianos y utilizamos métodos de Markov Chain Monte Carlo para obtener muestras del posterior, podemos calcular, para cada jugador, la probabilidad de que \(\delta_i\) sea mayor que 0. Con estas probabilidades, es posible construir el siguiente histograma resumen:
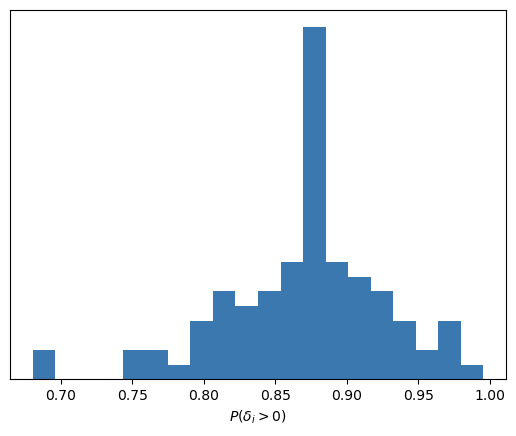
Luego, sin importar el rookie en el que nos fijemos, siempre concluiremos que tiene una probabilidad entre moderada y alta de ser más efectivo en los segundos lanzamientos que en los primeros.
Para finalizar, comparemos la distribución a posteriori de \(\delta\) del modelo agrupado con el posterior de \(\mu_\delta\) del modelo parcialmente agrupado, ya que ambas representan la misma cantidad: el diferencial promedio en la probabilidad de acierto entre un segundo y un primer lanzamiento.
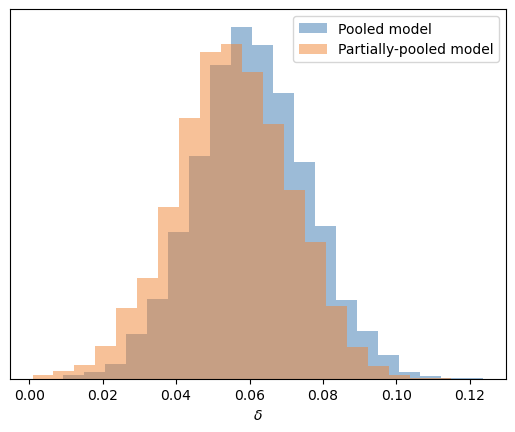
Afortunadamente, no tenemos que reportar sorpresas. Ambos modelos nos conducen hacia conclusiones prácticamente similares sobre el \(\delta\) promedio, aunque se puede mencionar que en el modelo jerárquico el posterior se encuentra levemente más regularizado hacia el 0 que en el modelo agrupado. Sin embargo, no debemos olvidar que utilizar un modelo jerárquico nos permitió obtener distribuciones a posteriori para cada jugador individual.
Ejemplos como este son los que me recuerdan por qué el enfoque bayesiano para la modelización estadística me gusta tanto.
Si bien podríamos habernos conformado con una simple prueba de hipótesis, como la que presentan en el artículo mencionado, la flexibilidad que ofrecen herramientas como PyMC nos permite ir varios pasos más allá. Propusimos un modelo jerárquico (nada trivial), lo implementamos en PyMC, y luego este, junto con nutpie, se encargaron de proporcionarnos muestras del posterior.
A partir de esas muestras, pudimos extraer varias conclusiones interesantes. No solo aquellas a nivel global, que confirman que los jugadores de básquet suelen fallar más en los primeros disparos que en los segundos (en línea con los resultados del artículo), sino también conclusiones específicas para cada jugador.
Y, por encima de todo, más allá de la utilidad práctica del modelo o de los insights que podamos obtener… ¿no es acaso super divertido jugar a la estadística bayesiana?