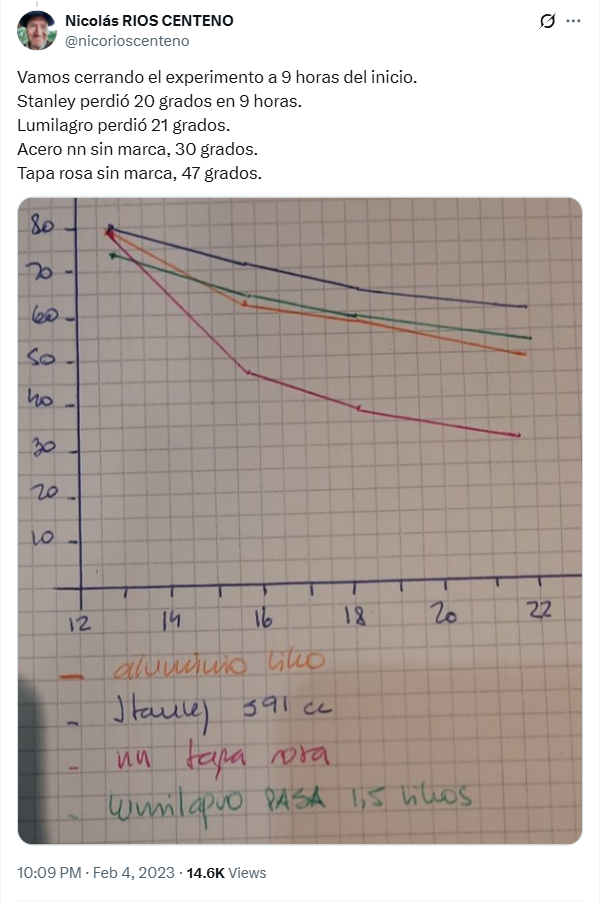
Hace algunas semanas, mientras navegaba por internet, me encontré con este posteo en la red social X. Allí, un productor agropecuario comentaba un experimento que estaba a punto de realizar para medir la capacidad de retener calor que ofrecían varios termos que tenía a su disposición.
El experimento consistió en colocar agua a 80 °C en cada uno de los termos y registrar su temperatura varias veces durante el día. Con los datos obtenidos, sería posible concluir sobre cuál termo ofrecía la mejor (y cuál la peor) capacidad de retener el calor.
Luego de varias mediciones, el autor del experimento compartió los resultados obtenidos:
De ellos se desprende que el termo “nn tapa rosa” fue el de peor desempeño, ya que el agua en su interior perdió calor considerablemente más rápidamente que en cualquier otro.
Ahora bien, la pregunta inevitable es: ¿cuál es el termo que ofrece una mejor retención de calor?
Para responder a esta incógnita usaremos un modelo Bayesiano basado en al Ley de enfriamiento de Newton.
Ley de enfriamiento de Newton
La ley de enfriamiento de Newton dice que la temperatura de un objeto cambia a una velocidad proporcional a la diferencia entre su temperatura y la del ambiente:
\[
\frac{dT(t)}{dt} = r \, (T_\text{env} - T(t))
\tag{1}\]
Cuanto mayor sea el valor de \(r\), peor será la capacidad del termo para retener temperatura. En otras palabras, el mejor termo será aquel con el valor de \(r\) más bajo (asumiendo que \(r > 0\)).
Elucidación de priors
En este artículo vamos a trabajar con modelos de la siguiente forma:
Es decir, para un tiempo dado \(t_i\), suponemos que el logaritmo de la diferencia entre la temperatura del agua y la temperatura ambiente sigue una distribución normal.
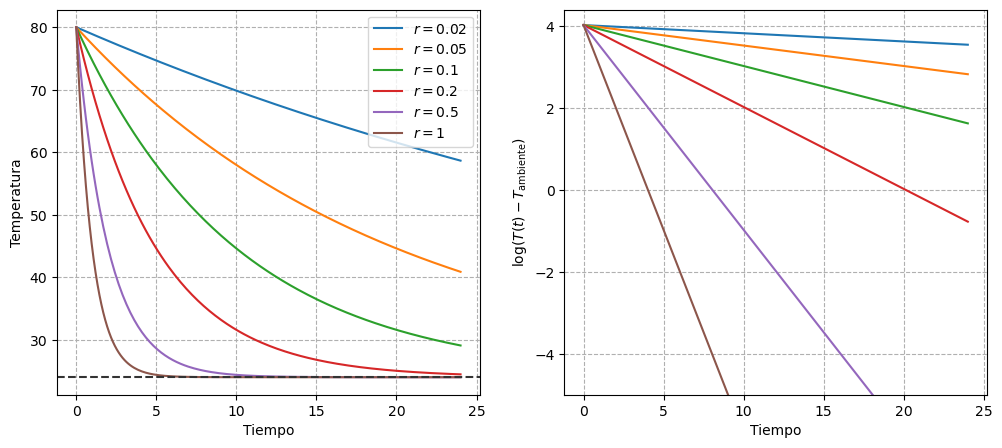
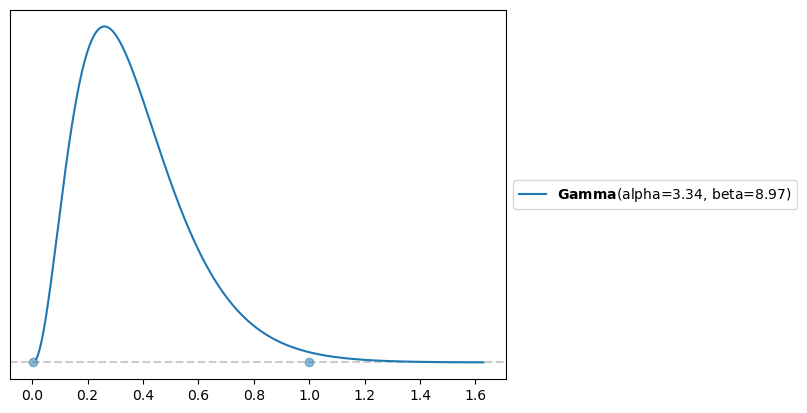
El parámetro de mayor interés es \(\beta\), que representa la tasa de enfriamiento del agua en el termo. En primer lugar, sabemos que su valor debe ser positivo, ya que la temperatura del agua inicial desciende hasta la temperatura ambiente. Además, a partir de las curvas mostradas en la Figura 1, podemos suponer que un rango razonable para este parámetro se encuentra en el intervalo \((0, 1)\). Este rango implica que el agua del termo alcanzaría la temperatura ambiente, como rápido, unas 5 horas después de haberlo llenado.
Usando PreliZ se puede obtener los parámetros de una distribución gamma que satisfagan nuestros requisitos.
Otro parámetro desconocido en nuestro modelo es \(\sigma\), el desvío estándar condicional. Es importante destacar que este desvío no está expresado en grados centígrados, ya que describe la variabilidad de \(\log(T(t_i) - T_\text{env})\), y no a la variablidad de \(T(t_i)\).
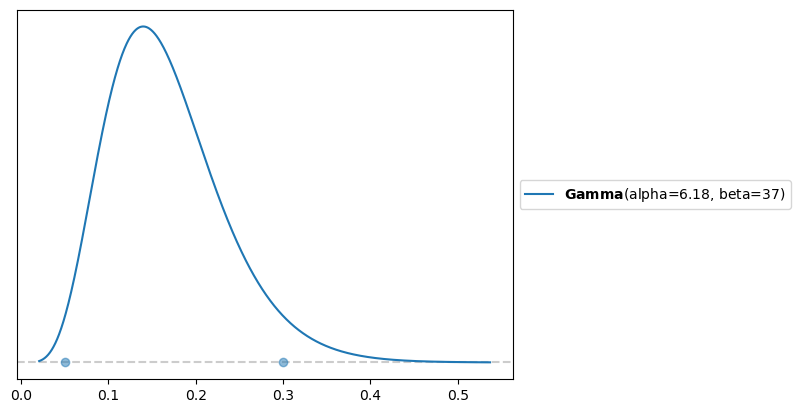
Al observar el panel derecho de la Figura 1, se puede notar que el rango de variación de la respuesta cubre apenas unas pocas unidades. Por eso, en este caso vamos a optar por una distribución gamma moderadamente informativa, que concentre una alta probabilidad en el intervalo \((0.05, 0.3)\).
Finalmente, podríamos elucidar una distribución a priori para \(\alpha\). Sin embargo, no es un parámetro con una interpretación intuitiva.
Lo que sí podemos hacer es establecer un prior para la temperatura inicial, que de manera implícita determine un prior para \(\alpha\).
Dado que en nuestro caso conocemos la temperatura del agua en \(t = 0\), consideraremos dos enfoques:
Valor fijo para \(T(0)\): en este caso, \(\alpha\) queda fijado a \(\log(T(0) - T_\text{env})\).
Distribución informativa para \(T(0)\): centrada en el valor observado. Usamos una distribución normal con media \(T(0)\) y desvío estándar de \(0.3\) °C, lo que equivale a expresar que la temperatura inicial difiere, como máximo, en un grado de la temperatura medida.
Datos
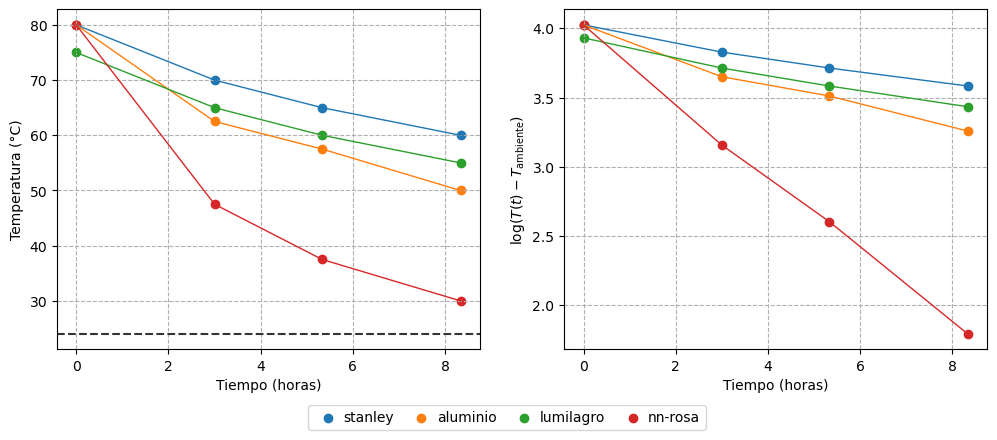
A partir de la foto compartida en el posteo de X, se pueden obtener los siguientes valores de tiempos y temperaturas:
A simple vista, el termo Stanley mantiene las temperaturas más altas en todo momento, mientras que el de tapa rosa destaca por su pobre desempeño. El Lumilagro, por su parte, muestra un rendimiento superior al de aluminio: aunque comenzó con una temperatura inicial más baja, su enfriamiento fue más lento. Por último, no puede afirmarse con certeza si el Stanley supera realmente al Lumilagro, ya que, si bien sus mediciones fueron siempre más altas, también partió con una temperatura mayor.
Por otra parte, el panel derecho de Figura 2 muestra una tendencia lineal para cada termo, lo que es consistente con el uso de un modelo lineal sobre \(\log(T(t) - T_\text{env})\).
Modelos
Modelo 1: Un termo + intercepto conocido
Antes de comenzar a trabajar con un modelo que considere a todas las marcas de termos, trabajemos con un modelo solo para la marca "stanley".
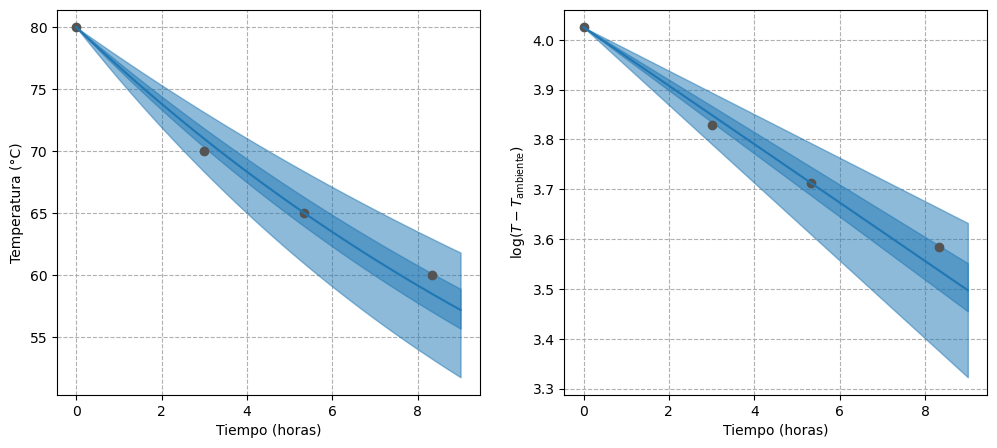
En el panel derecho de Figura 3 se muestra la recta de regresión ajustada, junto con los intervalos de credibilidad del 50% y 95%, en la escala de datos transformada, mientras que en el panel izquierdo se muestran los resultados en la escala original. La recta de regresión se ajusta adecuadamente a los puntos, aunque la incertidumbre asociada a su estimación aumenta a medida que transcurre el tiempo. Por otro lado, la nula incertidumbre en \(t=0\) se explica porque el intercepto tiene un valor fijo.
Modelo 2: Un termo + intercepto desconocido
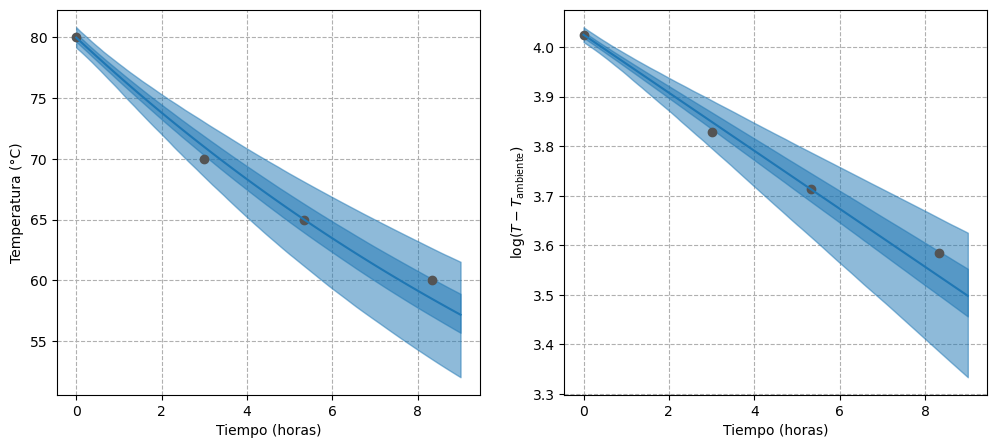
En este segundo modelo seguimos trabajando con un solo termo. La diferencia está en que, en vez de fijar la temperatura inicial al valor observado, le asignamos una distribución a priori muy informativa. De esta forma, seguimos incorporando la información que ya conocemos, pero no forzamos a la recta de regresión a pasar por un punto fijo.
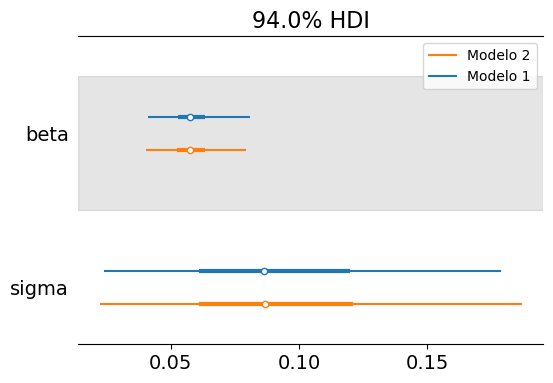
Los posteriors marginales de beta y sigma son prácticamente idénticos a los del primer modelo. En otras palabras, las conclusiones que se extraen sobre beta y sigma son similares a las que se obtienen cuando se usa una temperatura inicial fija. Además, los tamaños efectivos de muestra resultan siempre superiores a los obtenidos previamente.
Modelo 3: Todas las marcas
Ahora que ya estamos familiarizados con el modelo para una sola marca, podemos extenderlo para trabajar con todas las marcas.
En lugar de tener un único T_0, alpha y beta, tendremos uno para cada marca. En PyMC, esto se logra usando dims, lo que nos permite trabajar con vectores de variables aleatorias en lugar de escalares.
1y = np.log(np.concatenate([temps for temps in data.values()]) - T_env)times = np.tile(time, 4)brand_idx = np.repeat(np.arange(4), 4)coords = {"brand": list(data)}with pm.Model(coords=coords) as model_3: T_0 = pm.Normal("T_0", mu=[v.item(0) for v in data.values()], sigma=0.5, dims="brand") alpha = pm.Deterministic("alpha", np.log(T_0 - T_env), dims="brand") beta = pm.Gamma("beta", alpha=3.3, beta=12.8, dims="brand") sigma = pm.Gamma("sigma", alpha=6.2, beta=37) mu = pm.Deterministic("mu", alpha[brand_idx] - beta[brand_idx] * times) pm.Normal("log(T - T_env)", mu=mu, sigma=sigma, observed=y)display(model_3.to_graphviz())with model_3: idata_3 = pm.sample(random_seed=random_seed, target_accept=0.95)
1
Se crean arreglos unidimensionales con las temperaturas, los tiempos y el índice de marca para todas las marcas. Además, se prepara un diccionario de coordenadas para poder usar dims="brand" en el modelo
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [T_0, beta, sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 2 seconds.
Veamos el resumen a posteriori que nos devuelve az.summary().
Lo primero que llama la atención es que las medias a posteriori de las temperaturas iniciales se dividen en dos grupos: uno con valores cercanos a 80 y otro en torno a 75. Este resultado tiene sentido, ya que la temperatura inicial fue de 80 °C para todos los termos, excepto para el Lumilagro, que fue de 75 °C.
Por su parte, los beta para cada termo también muestran cierta heterogeneidad. En este caso, es posible concluir que el termo “nn-rosa” es el que presenta la mayor pérdida de calor (mayor valor de beta), aunque no es posible determinar con certeza cuál de ellos ofrece la mejor capacidad de retener de temperatura.
Finalmente, observamos que los tamaños efectivos de muestra oscilan entre 2000 y 4000, superando en todos los casos a los obtenidos en los modelos previos. Esto sugiere que el posterior presenta una geometría más accesible para el sampler NUTS que utiliza PyMC.
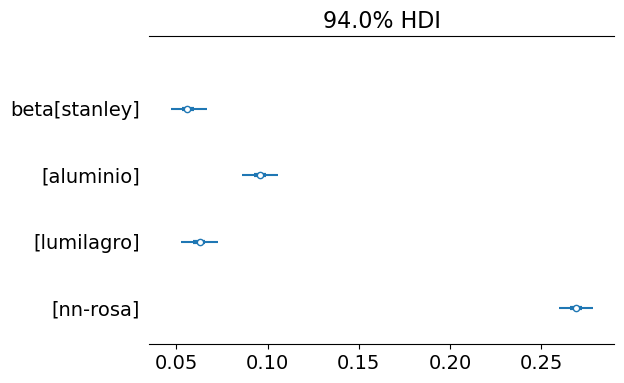
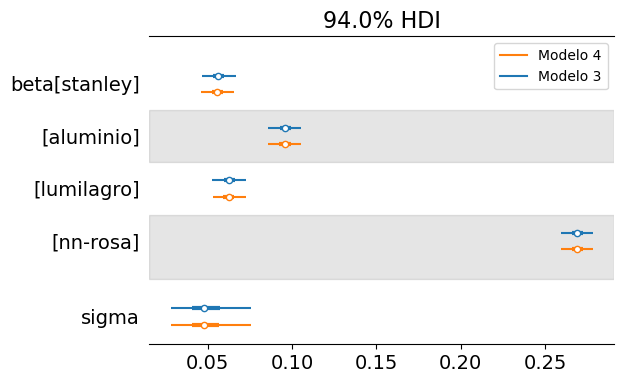
Si usamos la función az.plot_forest() podemos obtener un resumen de la distribución marginal de beta para cada marca:
Como se mencionó anteriormente, el “nn-rosa” presenta la mayor pérdida de calor, seguido por el termo “aluminio”, y finalmente los termos “lumilagro” y “stanley”. A simple vista, podría parecer que el “stanley” tiene una mejor capacidad para conservar la temperatura, aunque este gráfico por sí solo no permite sacar conclusiones certeras.
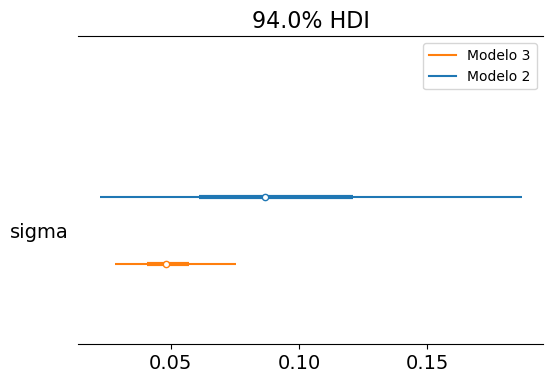
Si bien el parámetro sigma no es relevante en sí mismo, resulta interesante explorar su distribución a posteriori, ya que ofrece una medida de la incertidumbre aleatoria alrededor de nuestra recta de regresión.
Al utilizar los datos de todos los termos en este tercer modelo, se obtiene una estimación de sigma con una incertidumbre considerablemente menor.
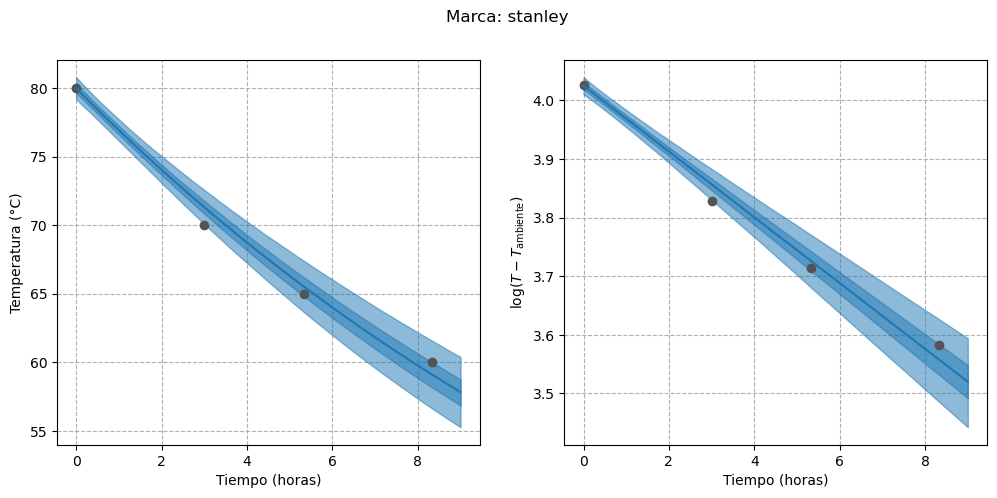
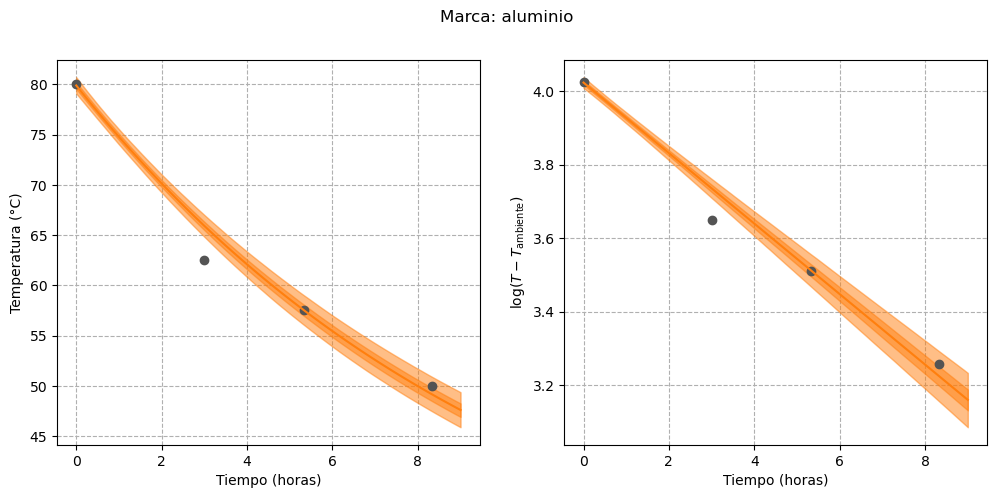
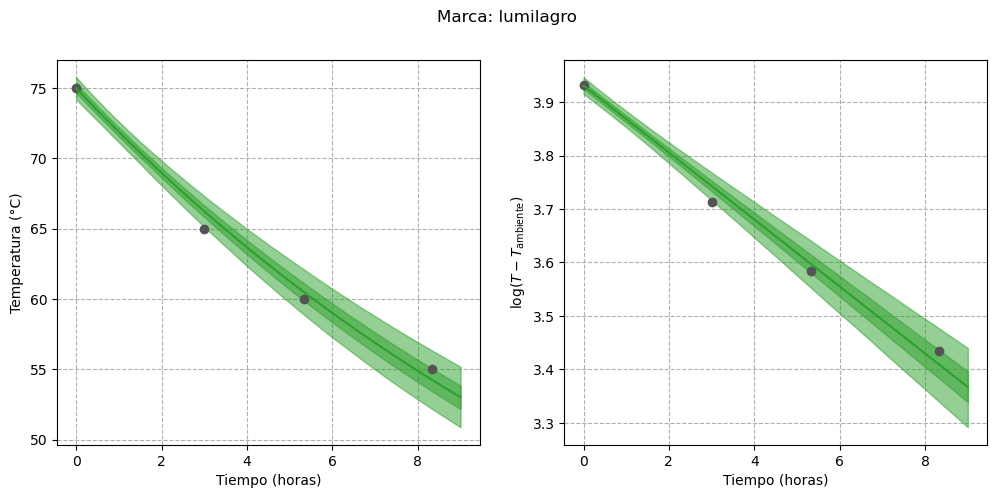
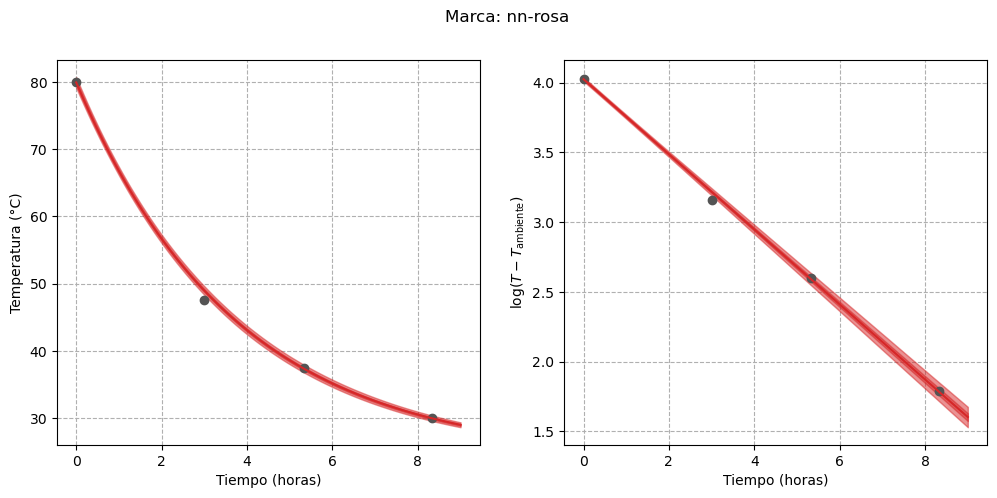
Finalmente, podemos visualizar las curvas estimadas para cada termos, tanto en su escala original como en la transformada:
for i, brand inenumerate(data): fig, axes = plot_estimated_curves( idata=idata_3.sel(brand=brand), x=time, y=data[brand], T_env=T_env, color=f"C{i}", ) fig.suptitle(f"Marca: {brand}")
En primer lugar, podemos notar que la incertidumbre en la recta de regresión para la marca “stanley” se redujo. Además, parece que en aquellos termos cuya temperatura del agua se acercó más rápidamente a la temperatura ambiente (es decir, los de menor capacidad para retener el calor) la incertidumbre es menor. El ejemplo más claro de este comportamiento es el termo “nn-rosa”, cuya temperatura prácticamente igualó a la del ambiente hacia el final del experimento.
Modelo 4: Todas las marcas + partial pooling para \(\beta\)
Para finalizar, vamos a crear un modelo jerárquico donde asumimos que las tasas de enfriamiento \(\beta\) pertenecen a una población común. De este modo, al compartir información entre los termos, esperamos obtener posteriors más precisos y estables, reflejando tanto las características individuales de cada termo como la tendencia general de la población.
Visualmente, se puede concluir que no hay diferencias entre los posteriors marginales de ambos modelos. En otras palabras, el partial pooling que ofrece el modelo jerárquico es prácticamente inexistente.
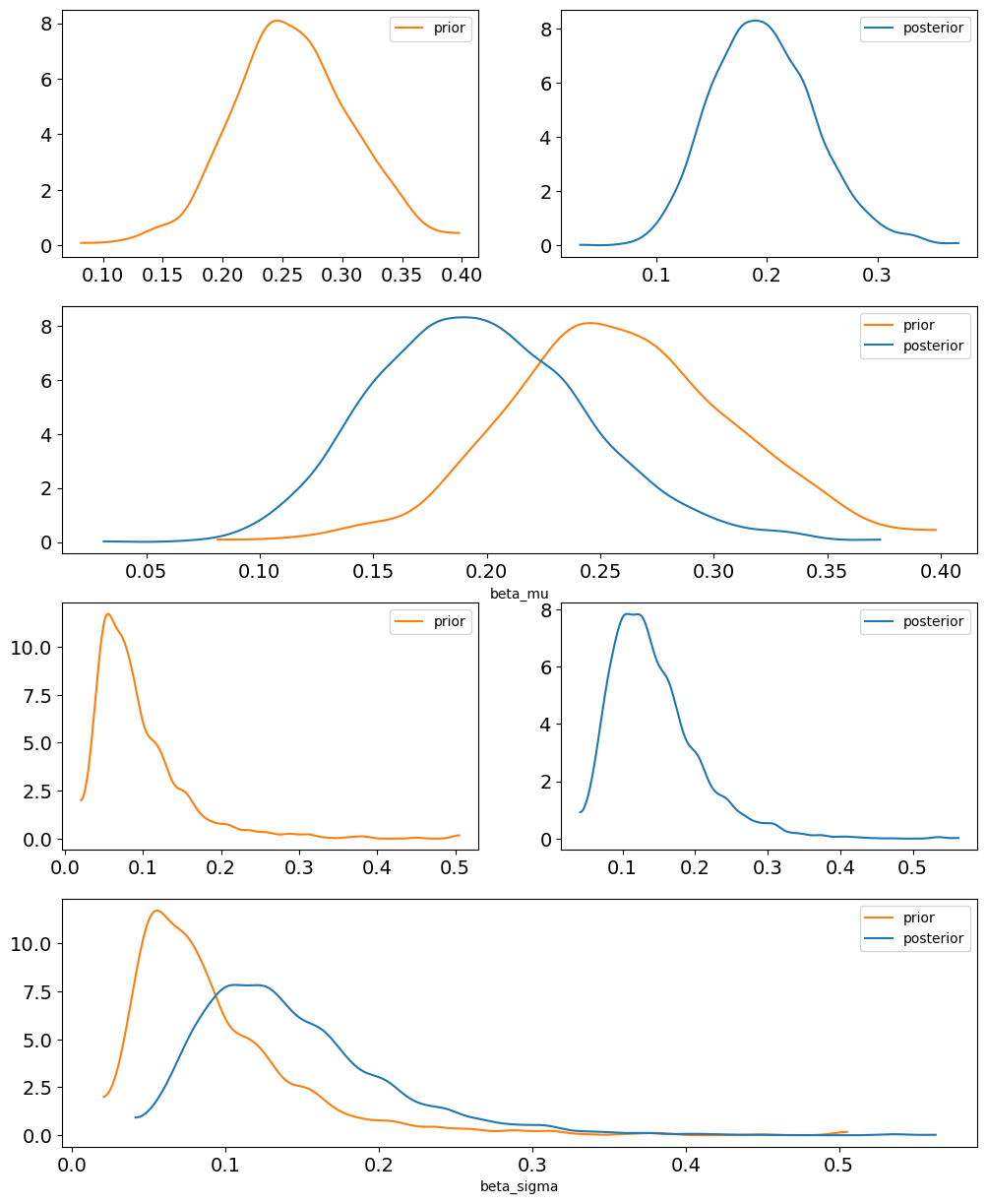
Para entender por qué no se observan diferencias entre los modelos, podemos examinar el prior y el posterior de la media y el desvío poblacional de \(\beta\) (beta_mu y beta_sigma).
En ambos casos, el posterior es muy similar al prior. Esto se debe a que la información disponible para estimar beta_mu y beta_sigma es insuficiente para obtener posteriors con baja incertidumbre. Este resultado es esperable, ya que el número de grupos es muy bajo (solo 4). En situaciones así, salvo que se disponga de abundante información a priori, el enfoque jerárquico no ofrecerá diferencias apreciables respecto a un modelo con parámetros independientes.
Conclusiones
¿Cuál es el mejor termo?
El mejor termo es aquel que presenta la menor tasa de enfriamiento \(\beta\).
En base a nuestro modelo, podemos obtener un resultado probabilístico de la siguiente manera:
Según nuestro modelo, hay un 82% de probabilidad de que el termo de la marca Stanley sea el que mejor conserva la temperatura.
En la práctica, nos corresponde a nosotros evaluar si esa probabilidad es suficiente para concluir que “stanley” es efectivamente superior a “lumilagro”. Por ejemplo, podría considerarse también la diferencia en grados que “stanley” logra mantener por encima de “lumilagro” a medida que pasa el tiempo.
Aunque el resultado no sea tan sorprendente, también es posible determinar de manera probabilística cuál es el peor de los termos:
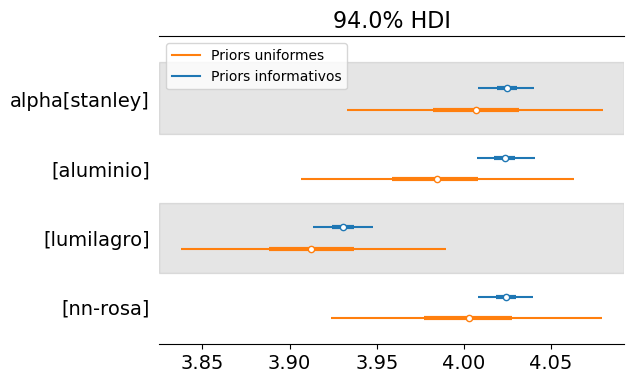
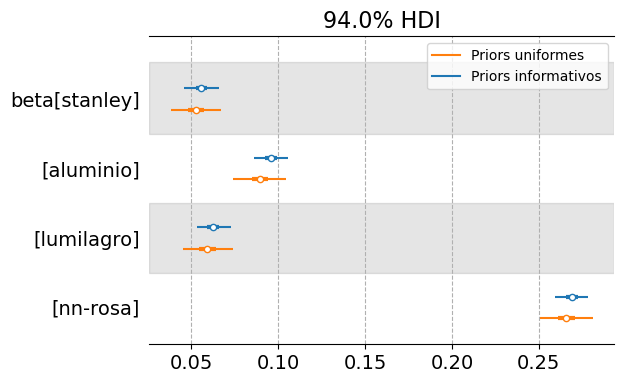
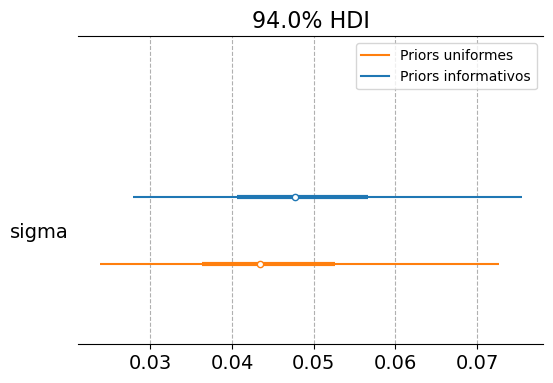
Tiene sentido preguntarse si el trabajo que conlleva la especificación de los priors vale la pena. Debajo, ajustamos el modelo multimarca utilizando priors uniformes y comparamos los resultados con los obtenidos anteriormente.
En base a un modelo con priors uniformes se extraen conclusiones en la misma dirección, pero con un nivel mayor de incertidumbre.
Un agradable Thomas Bayes tomando mate
Notas
En este blog no hacemos uso de los traceplots porque las cadenas siempre se mezclan bien y resulta suficiente usar el tamaño efectivo de muestra y el \(\hat{R}\).↩︎