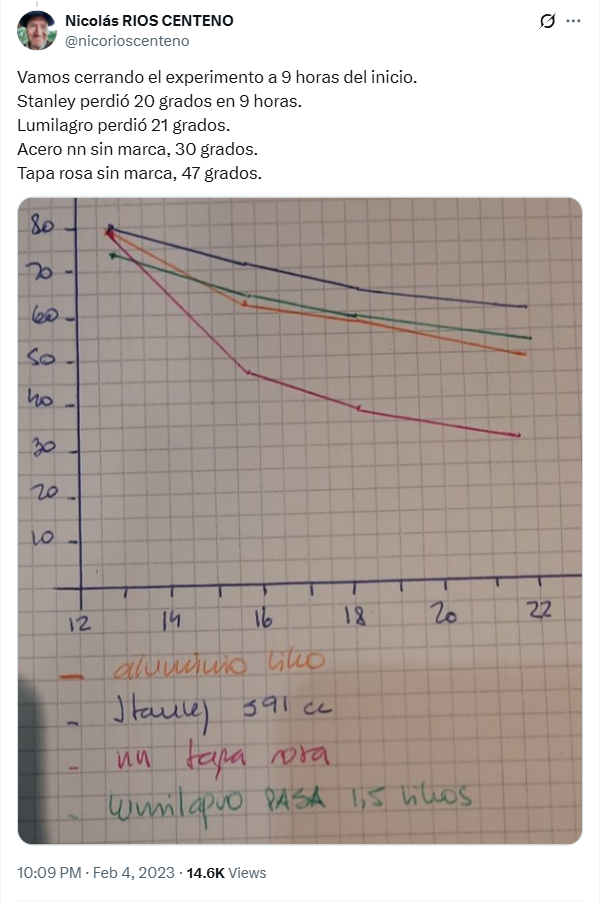
A few weeks ago, while browsing the internet, I came across this post on the social network X. There, a farmer described an experiment he was about to conduct to measure the heat retention capacity of several thermoses he had on hand.
The experiment involved pouring water at 80 °C into each thermos and recording its temperature several times throughout the day. With the collected data, it would be possible to determine which thermos had the best—and which had the worst—heat retention capacity.
After several measurements, the author of the experiment shared the results obtained:
From these results, it can be concluded that the “nn tapa rosa” thermos was the worst performer, as the water inside lost heat considerably more quickly than in any other thermos.
Now, the inevitable question is: which thermos offers the best heat retention?
To answer this question, we will use a Bayesian model based on Newton’s Law of Cooling.
Newton’s Law of Cooling
Newton’s law of cooling states that the temperature of an object changes at a rate proportional to the difference between its temperature and the ambient temperature:
\[
\frac{dT(t)}{dt} = r \, (T_\text{env} - T(t))
\tag{1}\]
The higher the value of \(r\), the worse the thermos’ ability to retain temperature. In other words, the best thermos will be the one with the lowest value of \(r\) (assuming that \(r > 0\)).
Prior elicitation
In this article, we will work with models in the following way:
That is, for a given time \(t_i\), we assume that the logarithm of the difference between the water temperature and the ambient temperature follows a normal distribution.
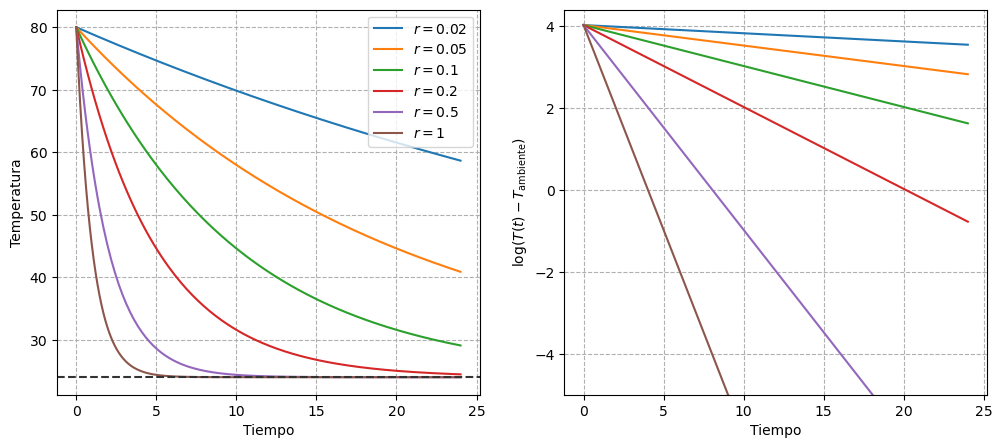
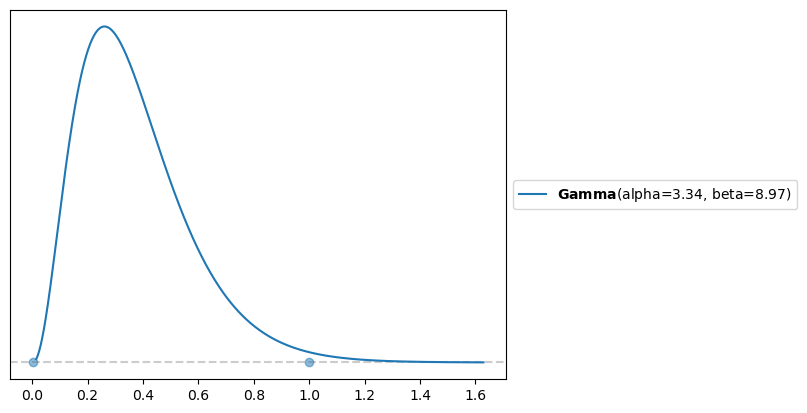
The parameter of greatest interest is \(\beta\), which represents the cooling rate of the water in the thermos. First, we know that its value must be positive, since the initial water temperature drops to the ambient temperature. Furthermore, based on the curves shown in Figure 1, we can assume that a reasonable range for this parameter is in the interval \((0, 1)\). This range implies that the water in the thermos would reach room temperature, at worst, about 5 hours after filling it.
Using PreliZ, we can obtain the parameters of a gamma distribution that satisfy our requirements.
Another unknown parameter in our model is \(\sigma\), the conditional standard deviation. It is important to note that this deviation is not expressed in degrees Celsius, as it describes the variability of \(\log(T(t_i) - T_\text{env})\), and not the variability of \(T(t_i)\).
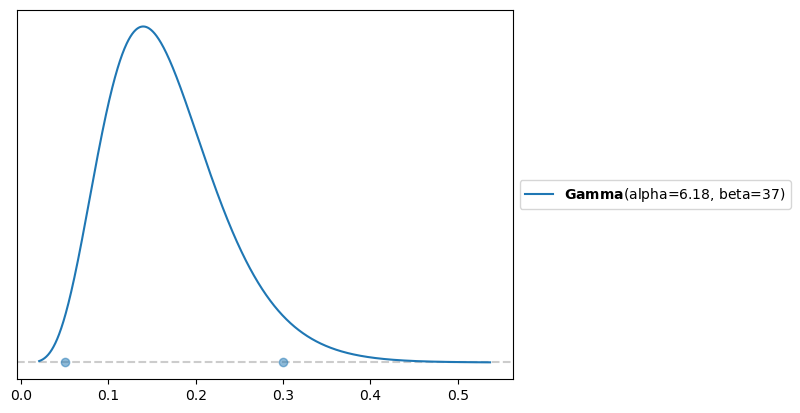
Looking at the right panel of Figure 1, we can see that the range of variation in the response covers only a few units. Therefore, in this case, we will opt for a moderately informative gamma distribution, which concentrates a high probability in the interval \((0.05, 0.3)\).
Finally, we could elicitate a prior distribution for \(\alpha\). However, it is not a parameter with an intuitive interpretation.
What we can do is establish a prior for the initial temperature, which implicitly determines a prior for \(\alpha\).
Since in our case we know the water temperature at \(t = 0\), we will consider two approaches:
Fixed value for \(T(0)\): in this case, \(\alpha\) is fixed to \(\log(T(0) - T_\text{env})\).
Informative distribution for \(T(0)\): centered on the observed value. We use a normal distribution with mean \(T(0)\) and standard deviation of \(0.3\) °C, which is equivalent to saying that the initial temperature differs by at most one degree from the measured temperature.
Data
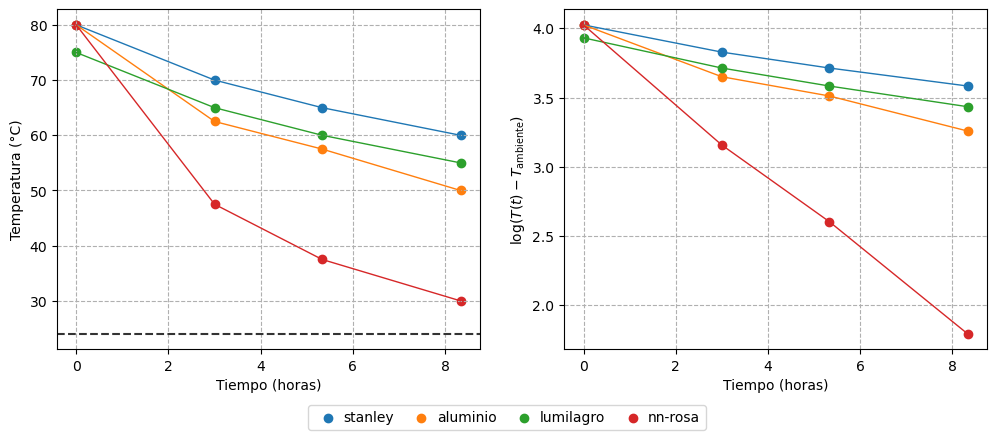
From the photo shared in X’s post, the following time and temperature values can be obtained:
At first glance, the “stanley” thermos maintains the highest temperatures at all times, while the one with the “nn tapa rosa” stands out for its poor performance. The “lumilagro”, on the other hand, performs better than the “aluminio” one: although it started with a lower initial temperature, it cooled down more slowly. Finally, it cannot be said with certainty whether the “stanley” thermos really outperforms the “lumilagro”, since, although its measurements were always higher, it also started with a higher temperature.
On the other hand, the right panel of Figure 2 shows a linear trend for each thermos, which is consistent with the use of a linear model on \(\log(T(t) - T_\text{env})\).
Modelos
Model 1: A thermos + known intercept
Before we start working with a model that considers all brands together, let’s work with a model for the brand “stanley” only.
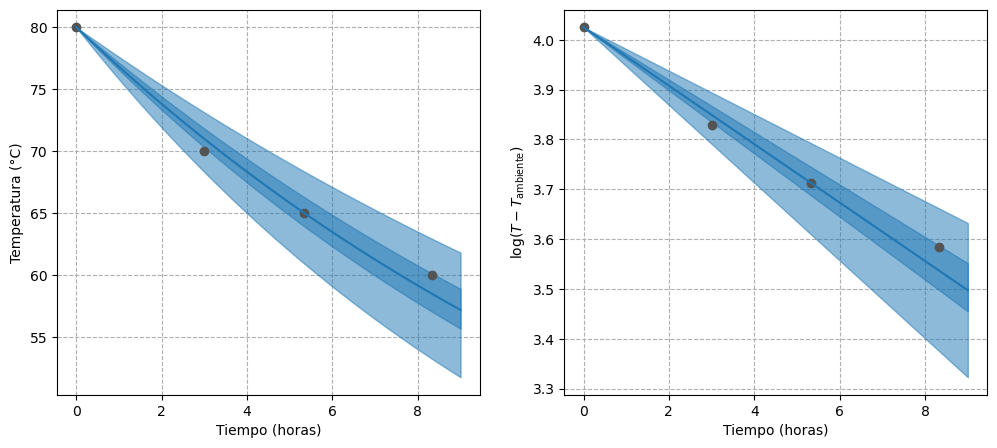
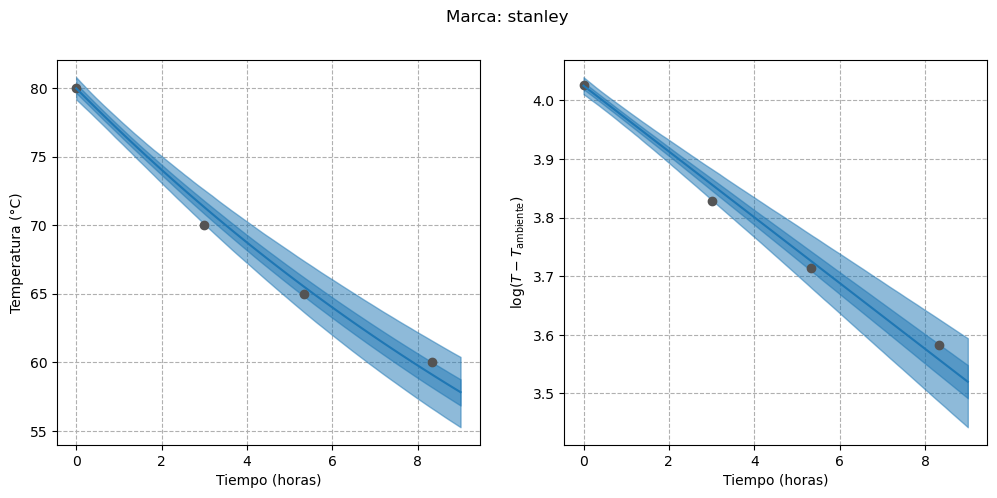
In the right panel of Figure 3, the fitted regression line is shown along with the 50% and 95% credible intervals on the transformed data scale, while the left panel shows the results on the original scale. The regression line fits the points well, although the uncertainty associated with its estimate increases over time. On the other hand, the absence of uncertainty at $t=0$ is explained by the fact that the intercept has a fixed value.
Model 2: One thermos + unknown intercept
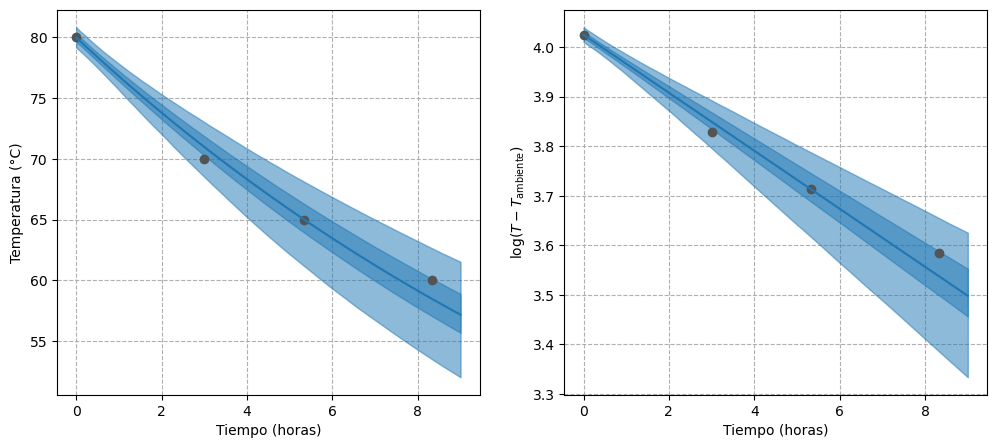
In this second model, we still work with a single thermos. The difference is that instead of fixing the initial temperature to the observed value, we assign it a highly informative prior distribution. This way, we continue incorporating the information we already have, but we don’t force the regression line to pass through a fixed point.
The marginal posteriors for beta and sigma are practically identical to those from the first model. In other words, the conclusions we can draw about beta and sigma are similar to those obtained when using a fixed initial temperature. In addition, the effective sample sizes are consistently higher than those obtained previously.
Model 3: All brands
Now that we are familiar with the model for a single brand, we can extend it to work with all brands.
Instead of having a single T_0, alpha, and beta, we will have one for each brand. In PyMC, this is achieved using dims, which allows us to work with vectors of random variables instead of scalars.
1y = np.log(np.concatenate([temps for temps in data.values()]) - T_env)times = np.tile(time, 4)brand_idx = np.repeat(np.arange(4), 4)coords = {"brand": list(data)}with pm.Model(coords=coords) as model_3: T_0 = pm.Normal("T_0", mu=[v.item(0) for v in data.values()], sigma=0.5, dims="brand") alpha = pm.Deterministic("alpha", np.log(T_0 - T_env), dims="brand") beta = pm.Gamma("beta", alpha=3.3, beta=12.8, dims="brand") sigma = pm.Gamma("sigma", alpha=6.2, beta=37) mu = pm.Deterministic("mu", alpha[brand_idx] - beta[brand_idx] * times) pm.Normal("log(T - T_env)", mu=mu, sigma=sigma, observed=y)display(model_3.to_graphviz())with model_3: idata_3 = pm.sample(random_seed=random_seed, target_accept=0.95)
1
One-dimensional arrays are created with the temperatures, times, and brand index for all brands. In addition, a coordinate dictionary is prepared so that dims="brand" can be used in the model.
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [T_0, beta, sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 2 seconds.
Let’s look at the posterior summary returned by az.summary().
The first thing that stands out is that the posterior means of the initial temperatures fall into two groups: one with values close to 80 and another around 75. This result makes sense, since the initial temperature was 80 °C for all thermoses except the Lumilagro, which was 75 °C.
The beta values for each thermos also show some heterogeneity. In this case, we can conclude that the “nn-rosa” thermos has the highest heat loss (largest beta value), although it’s not possible to determine with certainty which one offers the best heat retention.
Finally, we observe that the effective sample sizes range from 2000 to 4000, exceeding in all cases those obtained in the previous models. This suggests that the posterior has a geometry more accessible to the NUTS sampler used by PyMC.
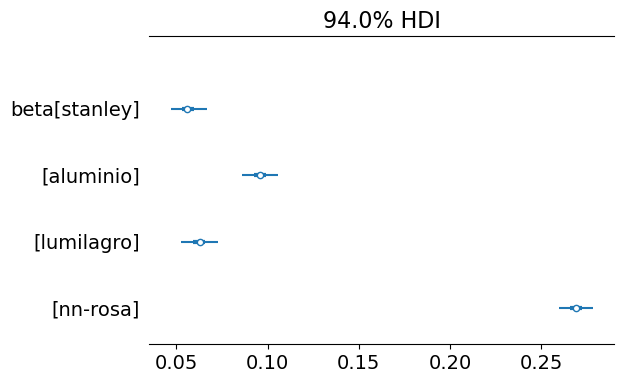
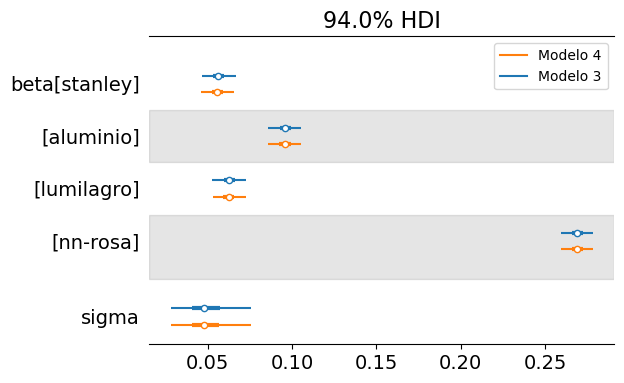
Using the az.plot_forest() function, we can obtain a summary of the marginal distribution of beta for each brand:
As mentioned earlier, the “nn-rosa” shows the highest heat loss, followed by the “aluminio” thermos, and finally the “lumilagro” and “stanley” thermoses. At first glance, it might seem that the “stanley” has a better ability to retain heat, although this plot alone does not allow us to draw definitive conclusions.
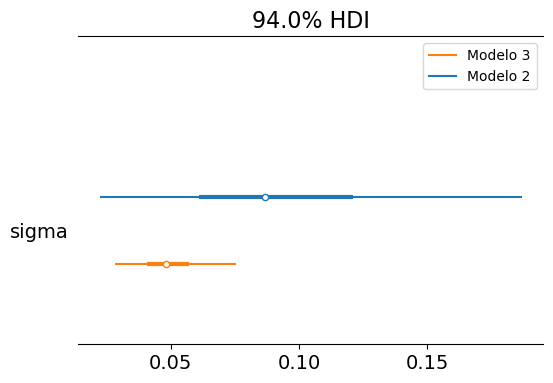
Although the sigma parameter is not inherently relevant, it is interesting to explore its posterior distribution, as it provides a measure of the random uncertainty around our regression line.
By using the data from all thermoses in this third model, we obtain an estimate of sigma with considerably less uncertainty.
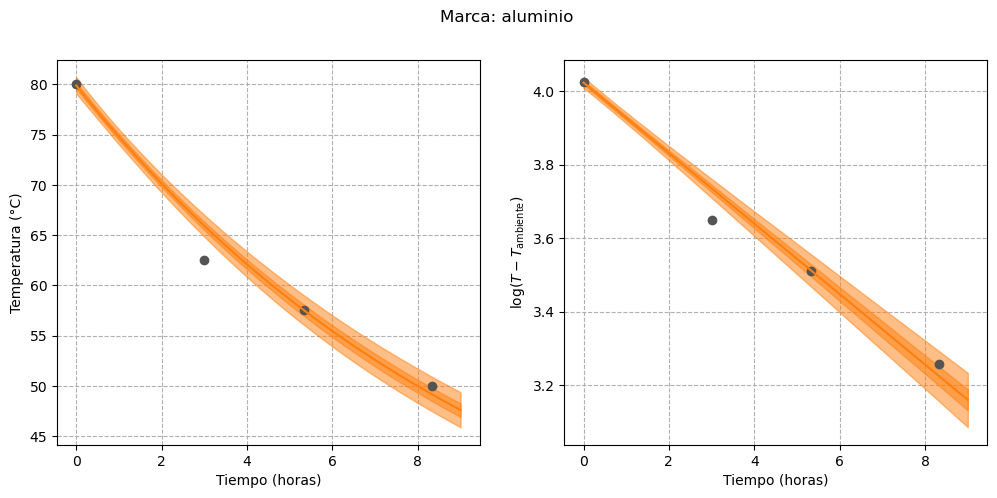
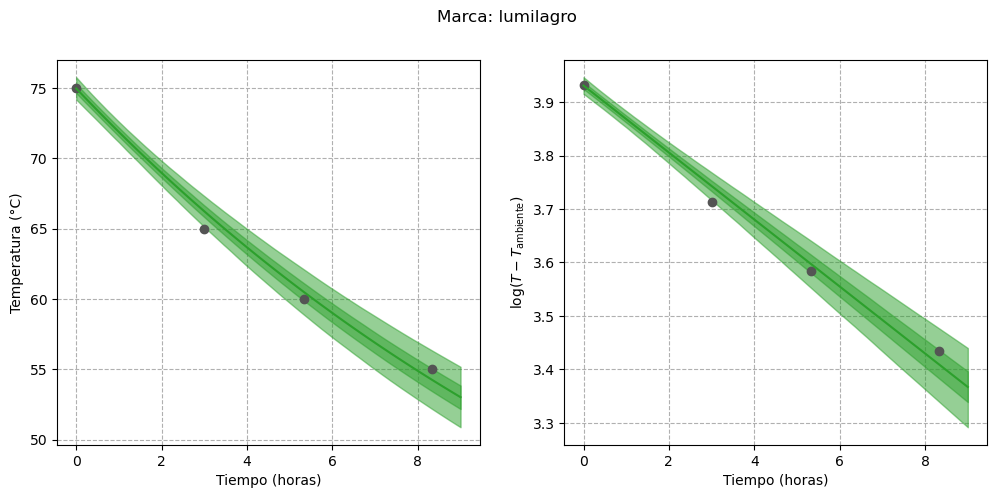
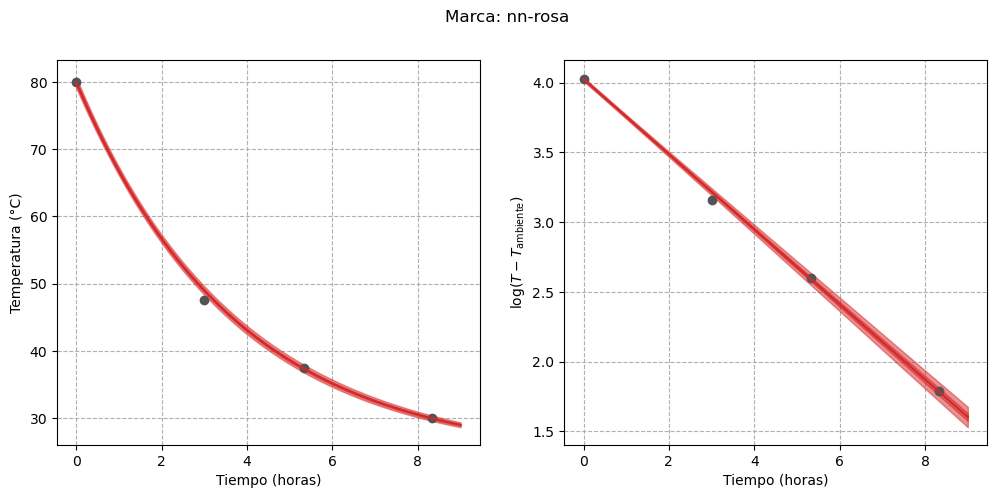
Finally, we can visualize the estimated curves for each thermos, both on their original scale and on the transformed scale:
for i, brand inenumerate(data): fig, axes = plot_estimated_curves( idata=idata_3.sel(brand=brand), x=time, y=data[brand], T_env=T_env, color=f"C{i}", ) fig.suptitle(f"Marca: {brand}")
First, we can see that the uncertainty in the regression line for the “stanley” brand has decreased. In addition, it seems that for those thermoses whose water temperature approached the ambient temperature more quickly (i.e., those with lower heat retention capacity), the uncertainty is smaller. The clearest example of this behavior is the “nn-rosa” thermos, whose temperature was almost equal to the ambient temperature by the end of the experiment.
Model 4: All brands + partial pooling for $$
Finally, we will create a hierarchical model in which we assume that the cooling rates \(\beta\) belong to a common population. By sharing information across thermoses in this way, we expect to obtain more precise and stable posteriors, reflecting both the individual characteristics of each thermos and the overall trend of the population.
The beta parameters still have a Gamma prior with a common mean and standard deviation. In this case, however, these parameters are unknown and determined by the data.
2
The function pz.maxent(pz.InverseGamma(), lower=0.01, upper=0.2, mass=0.95) is used.
3
Samples from the prior are drawn to generate Figure 4.
Sampling: [T_0, beta, beta_mu, beta_sigma, log(T - T_env), sigma]
Initializing NUTS using jitter+adapt_diag...
/home/tomas/miniconda3/envs/pymc-env/lib/python3.12/site-packages/pytensor/tensor/elemwise.py:710: RuntimeWarning: invalid value encountered in log
variables = ufunc(*ufunc_args, **ufunc_kwargs)
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [T_0, beta_mu, beta_sigma, beta, sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 3 seconds.
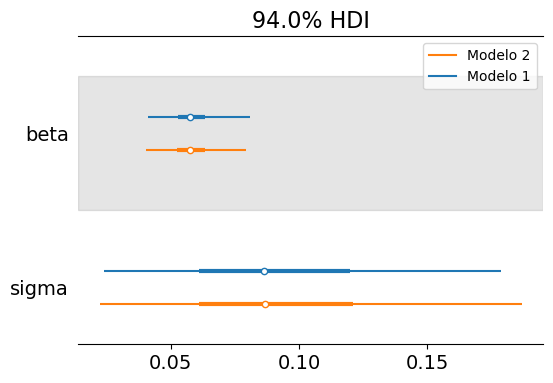
Below are the marginal posteriors of \(\beta\) and \(\sigma\) for both the non-hierarchical and hierarchical models:
Visually, we can conclude that there are no differences between the marginal posteriors of the two models. In other words, the partial pooling provided by the hierarchical model is practically nonexistent.
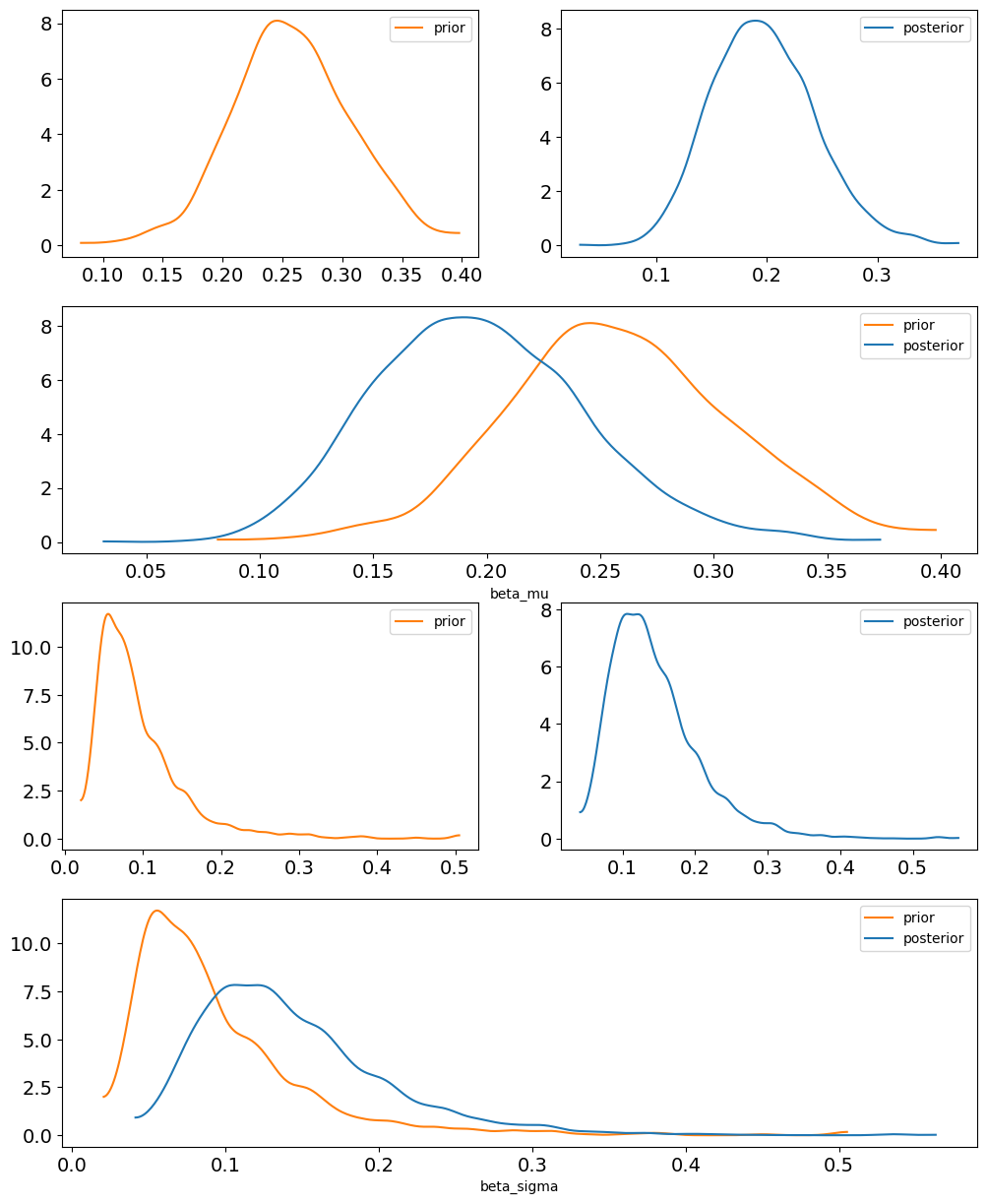
To understand why no differences are observed between the models, we can examine the prior and posterior of the population mean and standard deviation of \(\beta\) (beta_mu and beta_sigma).
In both cases, the posterior is very similar to the prior. This is because the available information to estimate beta_mu and beta_sigma is insufficient to obtain posteriors with low uncertainty. This result is expected, since the number of groups is very small (only 4). In situations like this, unless strong prior information is available, the hierarchical approach will not yield appreciable differences compared to a model with independent parameters.
Conclusions
Which is the best thermos?
The best thermos is the one with the lowest cooling rate $$.
Based on our model, we can obtain a probabilistic result as follows:
According to our model, there is an 82% probability that the “stanley” thermos is the one that best retains heat.
In practice, it is up to us to decide whether that probability is sufficient to conclude that “stanley” is indeed superior to “lumilagro”. For example, we could also consider the difference in degrees that the “stanley” manages to maintain above the “lumilagro” over time.
Although the result is not particularly surprising, it is also possible to determine probabilistically which is the worst thermos:
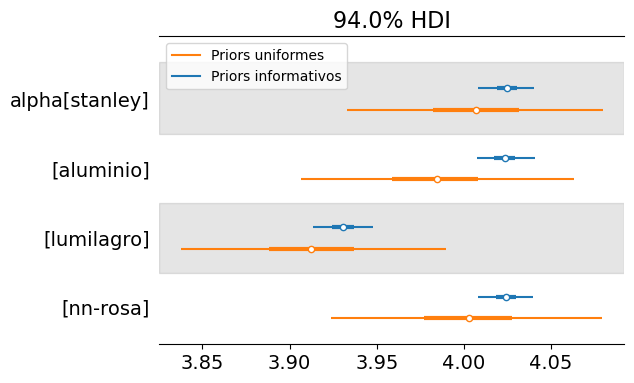
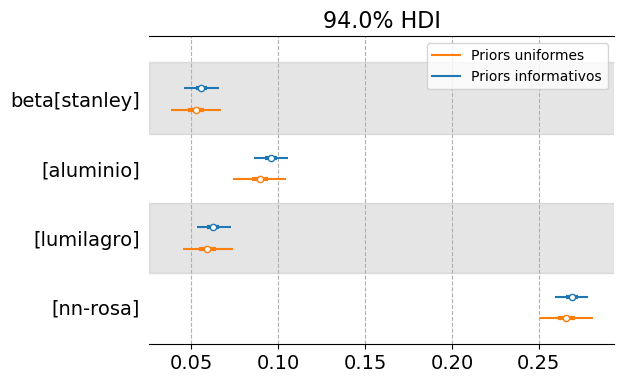
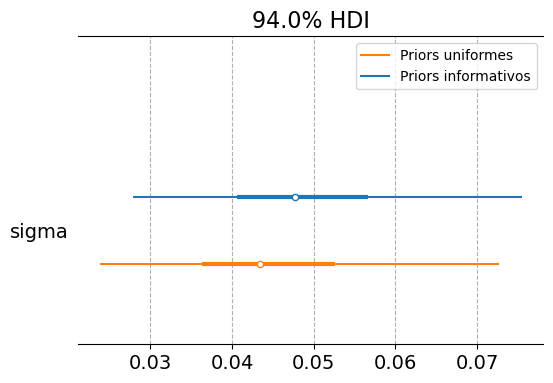
It is reasonable to ask whether the effort involved in specifying priors is worthwhile. Below, we fit the multi-brand model using uniform priors and compare the results with those obtained previously.
Based on a model with uniform priors, we reach conclusions in the same direction, but with a higher level of uncertainty.
That’s all folks
A lovely Thomas Bayes enjoying mate
Footnotes
En este blog no hacemos uso de los traceplots porque las cadenas siempre se mezclan bien y resulta suficiente usar el tamaño efectivo de muestra y el \(\hat{R}\).↩︎