The goal is to replicate the example in Section 4.1 in which the authors use the R2D2 prior in a mixed-effects logistic regression model applied to the gambia dataset from the {geoR} package in R.
First, I implement the model in PyMC and obtain results similar to those reported in the paper and then, I show how alternative priors and a different parameterization can make inference faster, more stable, and less uncertain.
Without further ado, let’s get into it.
Code
import arviz as azimport matplotlib.pyplot as pltimport numpy as npimport polars as plimport pymc as pmimport xarray as xrfrom scipy import specialfrom utils import WGBP, LogisticFamilyrandom_seed =sum(map(ord, "gambia"))def compute_conditional_R2(pi): mu_var = pi.var("__obs__") var_mean = (pi * (1- pi)).mean("__obs__")return mu_var / (mu_var + var_mean)def plot_priors(ds, var_names, axes):for ax, var_name inzip(axes, var_names): var_dims = ds[var_name].dimsiflen(var_dims) >2: dim_name = var_dims[-1]for i, (_, arr) inenumerate(ds[var_name].groupby(dim_name)): az.plot_dist(arr, color=f"C{i}", ax=ax)else: az.plot_dist(ds[var_name], ax=ax) ax.set(title=var_name, yticks=[])return axes
The data
The dataset contains data related to \(n = 2035\) children from \(L = 65\) villages in The Gambia, Africa. The response variable \(Y_i\) (pos) equals 1 if child \(i\) tested positive for malaria and 0 oterwise. There are \(p=5\) additional explanatory variables:
age: the child’s age.
netuse: whether the child regularly sleeps under a bed net.
treated: whether the bed net was treated.
green: a measure of vegetation greenness in the immediate vecinity of the village.
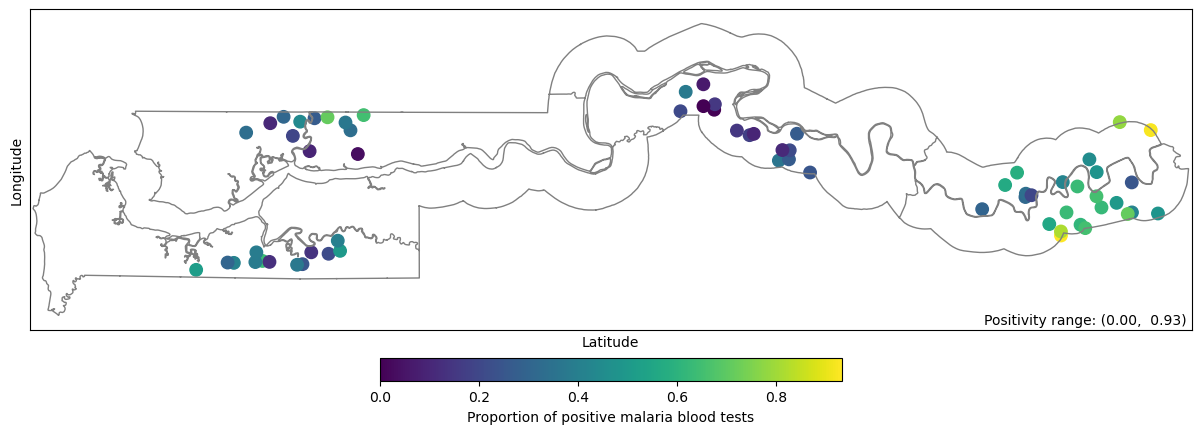
Figure 1: Proportion of positive tests per village in The Gambia, Africa.
Figure 1 shows that positivity rates vary widely across villages, ranging from 0% to 93%. There is spatial correlation in these rates: villages located near high-positivity villages tend to have higher positivity themselves, and the same holds for low-positivity villages. At a broader regional scale, positivity rates are highest in the eastern part of the country, moderate in the west, and lowest in the central region. This spatial correlation is mostly local, with nearby villages showing similar rates while villages farther apart show little or no association.
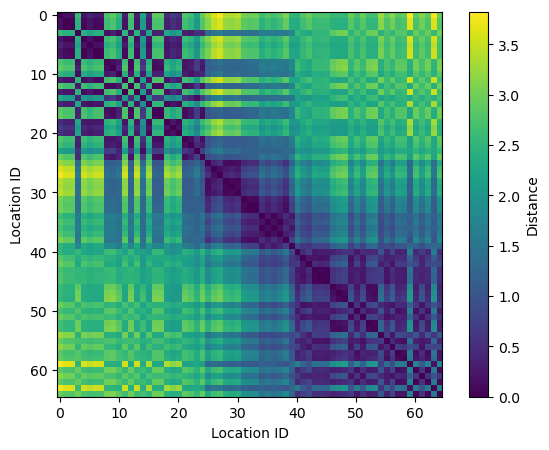
Below, we compute the distance matrix following the approach of Yanchenko et al. (2024) and then display it.
\(d_{ij}\) is the (standardized) distance between villages \(i\) and \(j\), and \(\rho > 0\) is the spatial range parameter.
For the fixed quantities, we have: \(\mu_0 = 0\), \(\tau_0^2 = 3\), \(\xi_1 = \xi_2 = 1\), and \(r\) is the maximum distance between pairs of villages.
The parameters \((a^*, b^*, c^*, d^*)\) of the GBP prior are found using the WGBP function I built for my previous blogpost. For \(R^2 \sim \text{Beta}(a=1, b=1)\), we have:
family = LogisticFamily(a=1, b=1, intercept=special.logit(df["pos"].mean()))params = WGBP(family)params
C is a matrix of shape (65, 65) that depends both on data (distance matrix) and a parameter (the spatial range parameter, \(\rho\)).
2
We use the fact that if \(V \sim \text{Beta}(a^*, b^*)\), then \(W = d^* (V / (1 - V))^{1/c^*} \sim \text{GBP}(a^*, b^*, c^*, d^*)\).
3
The prior on \(\boldsymbol{\beta}\) uses a diagonal covariance matrix, so we can use pm.Normal.
4
The prior on \(\boldsymbol{\gamma}\) does not, so we have to use pm.MvNormal.
The original paper obtains 10000 draws from 1 chain, here I’m going to get 10000 draws from 4 chains. Keep in mind that while I’m using NUTS, they used a Gibbs sampler.
with model: idata = pm.sample( draws=2500, target_accept=0.9, random_seed=random_seed, progressbar=False )
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [rho, V, phi, alpha, beta, gamma]
Sampling 4 chains for 1_000 tune and 2_500 draw iterations (4_000 + 10_000 draws total) took 78 seconds.
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
Before diving into the traceplots, we compute the conditional bayesian \(R^2\) introduced in Gelman et al. (2019), which is also computed and presented in the vignettes of the paper.
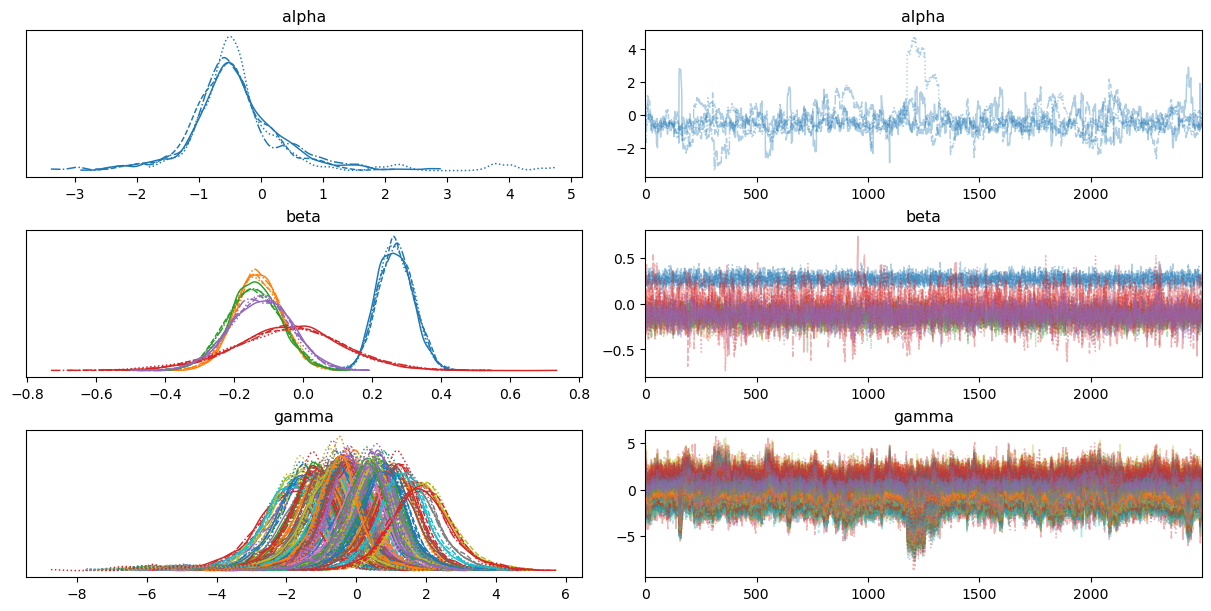
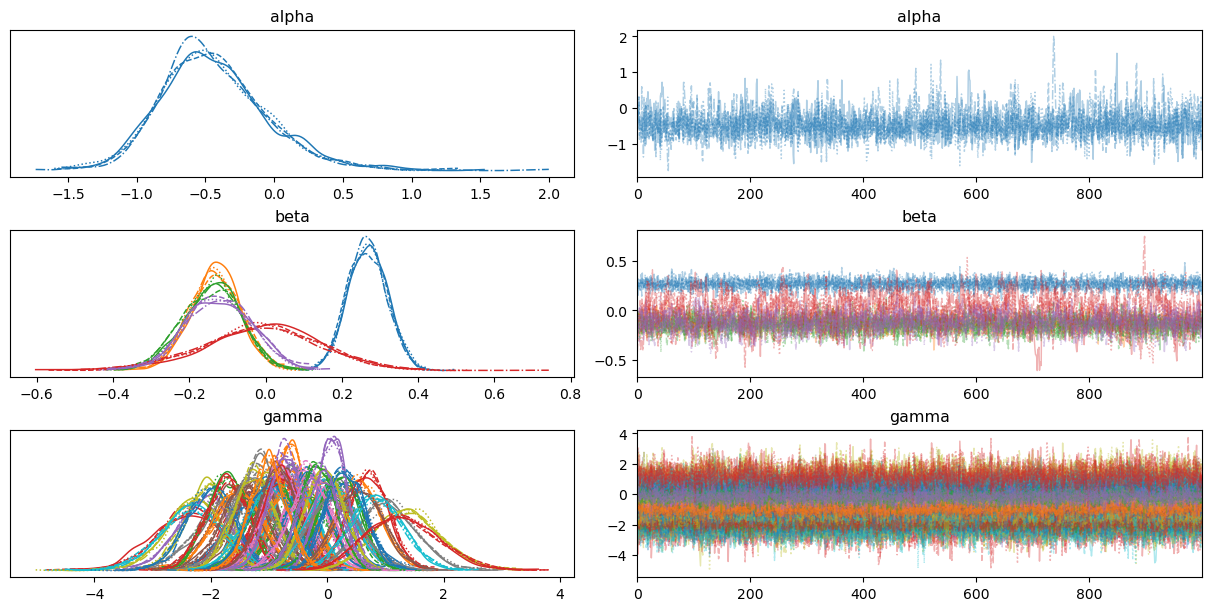
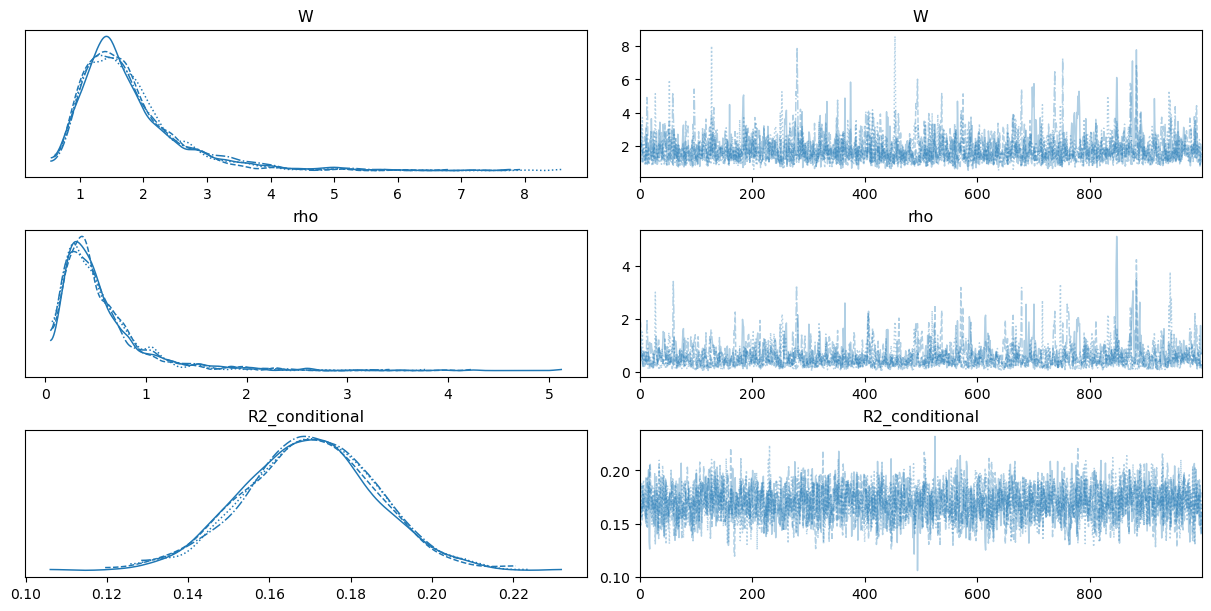
Looking at the traceplots, we can notice some signs of high autocorrelation and poor mixing in \(\alpha\) as well as correlation between the \(\gamma_i\) parameters. On the other hand, traces for \(\beta_j\) look fine.
If you run the code in the vignettes, you should find that the marginal posteriors are very similar to mine, at least by visual inspection, which allow us to conclude the implementation above is a succesful one.
A closer look
The blog post could have finished in the previous section. It already shows how to use the R2D2 prior for mixed-effects logistic regressions in PyMC, and the results obtained are similar to those in the paper.
However, we can take a look at a few diagnostic measures, which will help us identify areas where the model could be improved.
Chains don’t mix well
I previously mentioned issues related to mixing and autocorrelation, which we can confirm by inspecting the default output of arviz.summary applied to \(\alpha\) and \(\gamma_i\).
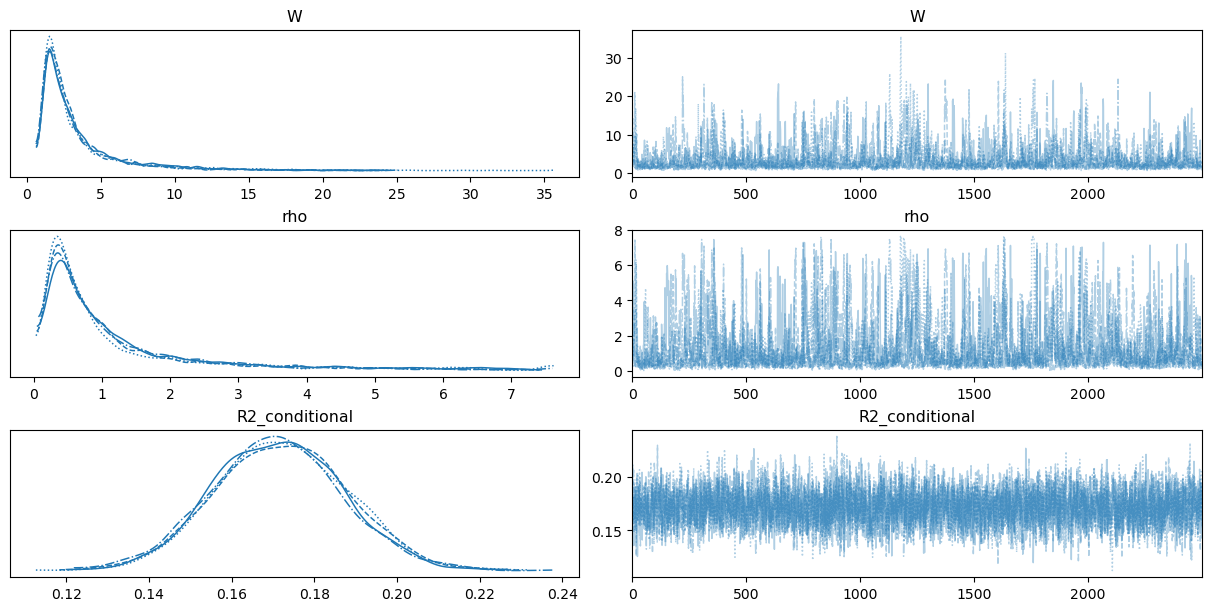
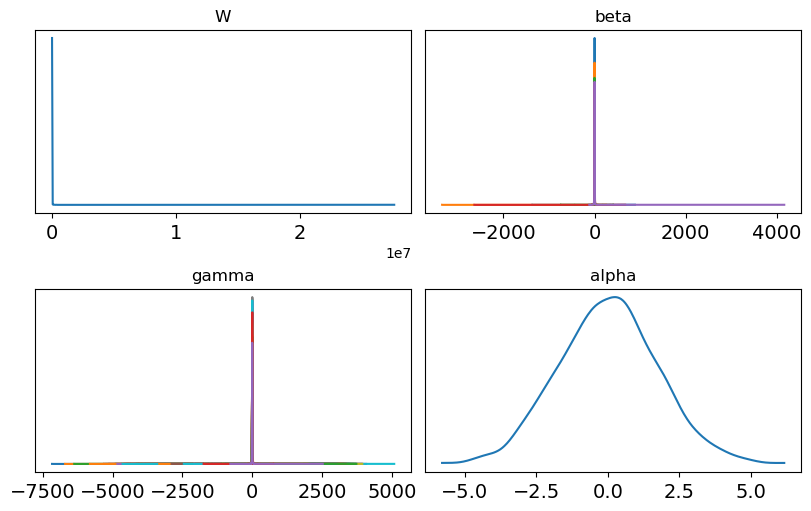
Marginal prior for W, \(\beta_j\), \(\gamma_i\), and \(\alpha\).
A flat prior on the marginal \(R^2\) induces a very heavy-tailed prior on \(W\), which in turn leads to heavy-tailed priors for \(\beta_j\) and \(\gamma_i\).
For \(\alpha\), the prior is not as heavy-tailed, but in a logistic regression context it could be made more concentrated, as the current specification still assigns non-negligible prior mass to implausible values.
Correlations between \(\alpha\) and \(\gamma_i\) are too large
The correlation between \(\alpha\) and each of the \(\gamma_i\) is always negative and large. Some negative correlation is expected in models with \(L+1\) intercept-like parameters (a global intercept plus \(L\) group effects) but only \(L\) identifiable group means: when the global intercept \(\alpha\) increases, the group-level deviations \(\gamma_i\) can offset it by decreasing.
This dependence creates a narrow, tilted geometry in the posterior, which makes it harder for NUTS to explore efficiently.
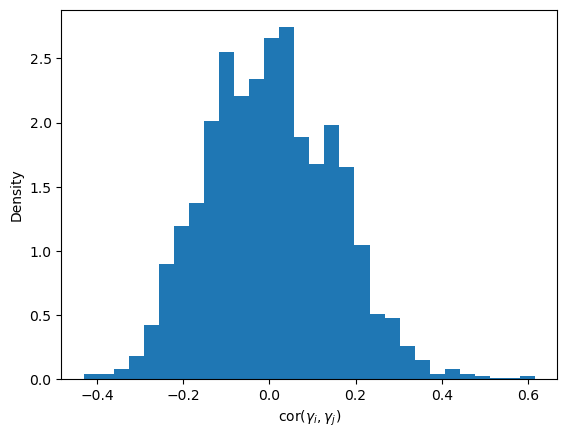
Correlations between \(\gamma_i\) and \(\gamma_j\) are too large
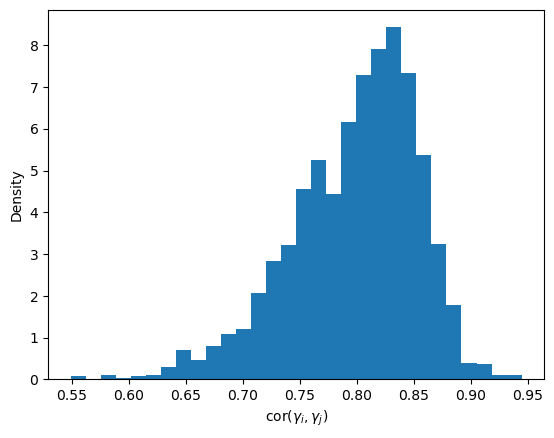
Finally, let’s have a look at the correlation between the \(\gamma_i\) themselves:
Not only is the correlation between \(\alpha\) and the \(\gamma_i\) large in magnitude, but the \(\gamma_i\) are also highly correlated with one another. Here these correlations are all positive. As before, this strong dependence makes the posterior geometry more difficult, so NUTS has a harder time exploring it efficiently.
A quick way to assess how much redundancy there is among parameters is to look at the eigenvalues of the correlation matrix, as in Principal Component Analysis. The ratio between the eigenvalues and the number of variables indicates the fraction of the total variability that is captured by the corresponding principal component.
eigenvals_1 = np.linalg.eigvals(corr_matrix)print(eigenvals_1[:3])print((eigenvals_1 / eigenvals_1.sum())[:3]) # n variables = sum(eigenvalues)
About 80% of the total variability in the posterior for \(\boldsymbol{\gamma}\) can be captured by a single coordinate. That’s a lot of redundancy!
An alternative proposal
I’m going to reimplement the same model, with a few tweaks:
I’m going to use a more informative prior on the marginal \(R^2\). This will result in a more sensible prior for \(W\) in the context of a logistic regression model.
I will decrease the prior variance for \(\alpha\), a value of \(3\) is larger than what we need in this context.
Finally, I’m going to change the model parametrization, see details when I write the model in PyMC.
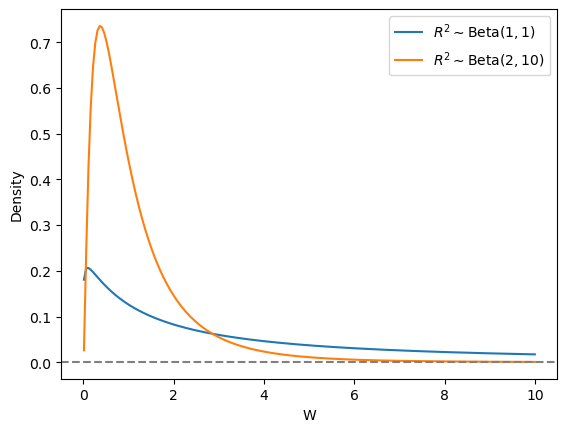
For the marginal \(R^2\) I’m going to use a \(\text{Beta}(2, 10)\) prior. The resulting prior on \(W\) concentrates most of the probability mass in a range that is more sensible than a \(\text{Beta}(1, 1)\), as you can see in Figure 2.
Figure 2: The Beta(1, 1) prior on \(R^2\) induces much heavier-tailed prior on \(W\) than Beta(2, 10).
The implementation in PyMC looks almost exactly the same:
with pm.Model(coords=coords) as model_2: rho = pm.Uniform("rho", lower=0, upper=2* r) C = np.exp(-dist / rho) V = pm.Beta("V", alpha=params_2[0], beta=params_2[1]) W = pm.Deterministic("W", (V / (1- V)) ** (1/ params_2[2]) * params_2[3]) phi = pm.Dirichlet("phi", a=np.ones(2))1 alpha = pm.Normal("alpha", mu=0, sigma=0.75) beta = pm.Normal("beta", mu=0, sigma=(1/ p * W * phi[0]) **0.5, dims="predictors")2 gamma = pm.MvNormal("gamma", mu=alpha, cov=phi[1] * W * C, dims="village") eta = X_std @ beta + gamma[village_idx] pi = pm.Deterministic("pi", pm.math.sigmoid(eta), dims="__obs__") pm.Bernoulli("y", p=pi, observed=y, dims="__obs__")
1
The prior standard deviation of \(\alpha\) is now 0.75, instead of \(\sqrt{3}\).
2
Change the parameterization for \(\boldsymbol{\gamma}\). I center the prior for \(\gamma_i\) directly around \(\alpha\), instead of centering them around 0 and then computing \(\alpha + \gamma_i\).
If we look at the marginal priors of the parameters we inspected before, we can see they span a more reasonable range now. The marginal priors for the \(\gamma_i\) are still a bit too wide, but they are not as heavy-tailed as before.
Next, we get 1000 draws across four chains using NUTS. Sampling is faster than before and completes without warnings.
Code
with model_2: idata_2.extend(pm.sample(target_accept=0.9, random_seed=random_seed, progressbar=False))idata_2.posterior["R2_conditional"] = compute_conditional_R2(idata_2.posterior["pi"])
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [rho, V, phi, alpha, beta, gamma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 19 seconds.
Something similar applies to the correlation between the \(\gamma_i\) themselves. While not all correlations are negligible in magnitude, their distribution is now centered around zero.
Looking at the eigenvalues, the share of variability captured by the first dimension drops from 80% to 15%, indicating that the correlations within \(\boldsymbol{\gamma}\) have decreased substantially.
eigenvals_2 = np.linalg.eigvals(corr_matrix)print(eigenvals_2[:3])print((eigenvals_2 / eigenvals_2.sum())[:3]) # n variables = sum(eigenvalues)
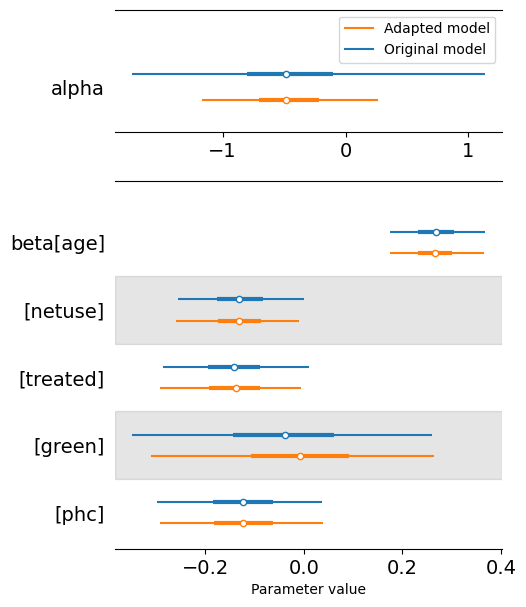
In both cases, the posterior for \(\alpha\) is centered at essentially the same value,but the adapted model produces a more concentrated distribution. This is expected since we used a more informative prior for \(\alpha\) and reduced its posterior correlation with \(\boldsymbol{\gamma}\). For \(\beta_j\), they look the same.
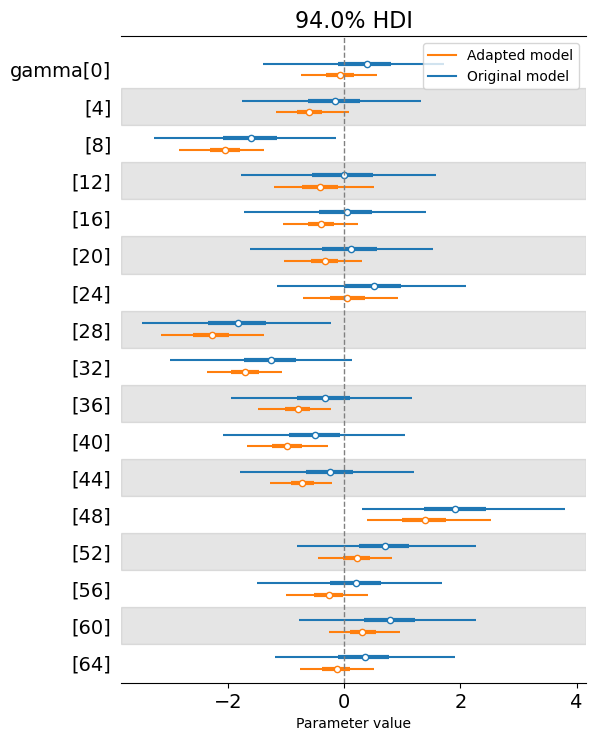
In some cases, the marginal posterior for \(\gamma_i\) is closer to 0. In others, it is farther away. But in every case, the adapted model produces a more concentrated posterior, indicating reduced uncertainty.
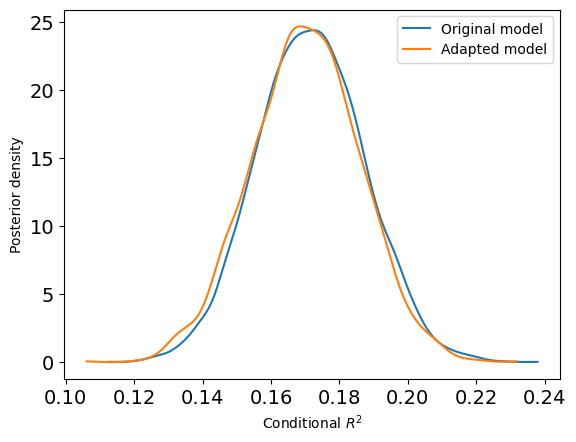
To wrap up, let’s compare the posterior distribution of the conditional \(R^2\) under the two models:
They are essentially identical: the changes to the priors and parameterization do not affect the posterior distribution of the conditional \(R^2\).
What’s next
With this post, I returned to the example where I started. It’s been quite a ride. I think this is the most challenging of the examples in Yanchenko et al. (2024).
Next, I’ll publish another post reproducing the remaining examples, where \(W\) has a closed-form solution. But that will have to wait until next year. Now, it’s time to go on vacation.
References
Gelman, Andrew, Ben Goodrich, Jonah Gabry, and Aki Vehtari. 2019. “R-Squared for Bayesian Regression Models.”The American Statistician 73 (3): 307–9. https://doi.org/10.1080/00031305.2018.1549100.
Yanchenko, Eric, Howard D. Bondell, and Brian J. Reich. 2024. “The R2D2 Prior for Generalized Linear Mixed Models.”The American Statistician 79 (1): 40–49. https://doi.org/10.1080/00031305.2024.2352010.